
1 框架概述
部署管理主要是基于ansible来对组件进行安装。
│
├─ansible_handler
│ │ README.md
│ │
│ ├─example 模板示例
│ │ │ example_playbooks.yml 示例playbook
│ │ │ example_vars.yml 示例变量文件
│ │ │
│ │ └─example 示例角色任务
│ │ ├─files 组件需要的文件目录,可以是软件包或运行时所需要的其他文件。
│ │ │ readme.md
│ │ │
│ │ ├─tasks 示例任务
│ │ │ config_example.yml 配置示例说明
│ │ │ install_example.yml 安装示例说明
│ │ │ main.yml 任务入口示例说明
│ │ │ start_example.yml 启动示例说明
│ │ │
│ │ └─templates 模板文件
│ │ example.j2 模板配置示例说明
│ │
│ ├─inventory 组件的主机列表
│ │ elasticsearch
│ │ fluentd
│ │ ...
│ │
│ ├─playbooks 组件的playbook入口文件
│ │ elasticsearch.yml
│ │ fluentd.yml
│ │ ...
│ │
│ ├─roles 组件角色任务
│ │ ├─elasticsearch
│ │ │ ├─tasks 组件的playbook中的具体task步骤
│ │ │ │ config_elasticsearch.yml 定义配置具体步骤。
│ │ │ │ install_elasticsearch.yml 定义安装具体步骤。
│ │ │ │ main.yml 任务执行的主脚本,会包含install、config、start以及自定义的yml文件。
│ │ │ │ start_elasticsearch.yml 定义启动步骤。
│ │ │ │
│ │ │ └─templates 组件安装过程中需要的模板文件。安装时会根据配置值生成实际的文件。
│ │ │ elasticsearch.j2
│ │ │
│ │ └─...
│ │
│ └─vars 组件的变量文件
│ elasticsearch_vars.yml
│ fluentd_vars.yml
│ ...
│
├─ansible_runner 调用ansible来执行任务的python接口
│ ansible_runner.py
│ inventory_builder.py
│ vault_handler.py
│ __init__.py
│
└─tasks 任务文件,由一系列有序的组件安装步骤组成
XXX_task.yml
2 添加组件步骤
2.1 默认组件模板
2.1.1 默认组件列表
当前提供的默认组件包括:
| 组件名称 | 安装方式 | 版本 | 部署位置 |
|---|---|---|---|
| zookeeper | dnf | 3.6.2 | all |
| kafka | dnf | 2.6.0 | all |
| prometheus | dnf | 2.20.0 | 主节点 |
| node_exporter | dnf | 1.0.1 | all |
| mysql | dnf | 8.0.26 | 主节点 |
| elasticsearch | dnf(官网镜像) | 7.14.0(随官网更新) | 主节点 |
| fluentd | dnf | 1.13.3 | all |
| fluent-plugin-elasticsearch | dnf | 5.0.5 | all |
| adoctor-check-executor | dnf | 1.0.1 | 主节点 |
| adoctor-check-scheduler | dnf | 1.0.1 | 主节点 |
| adoctor-diag-executor | dnf | 1.0.1 | 主节点 |
| adoctor-diag-scheduler | dnf | 1.0.1 | 主节点 |
| gala-ragdoll | dnf | 1.0.1 | 主节点 |
| gala-gopher | dnf | 1.0.1 | all |
| gala-spider | dnf | 1.0.1 | 主节点 |
2.1.2 默认组件安装依赖关系
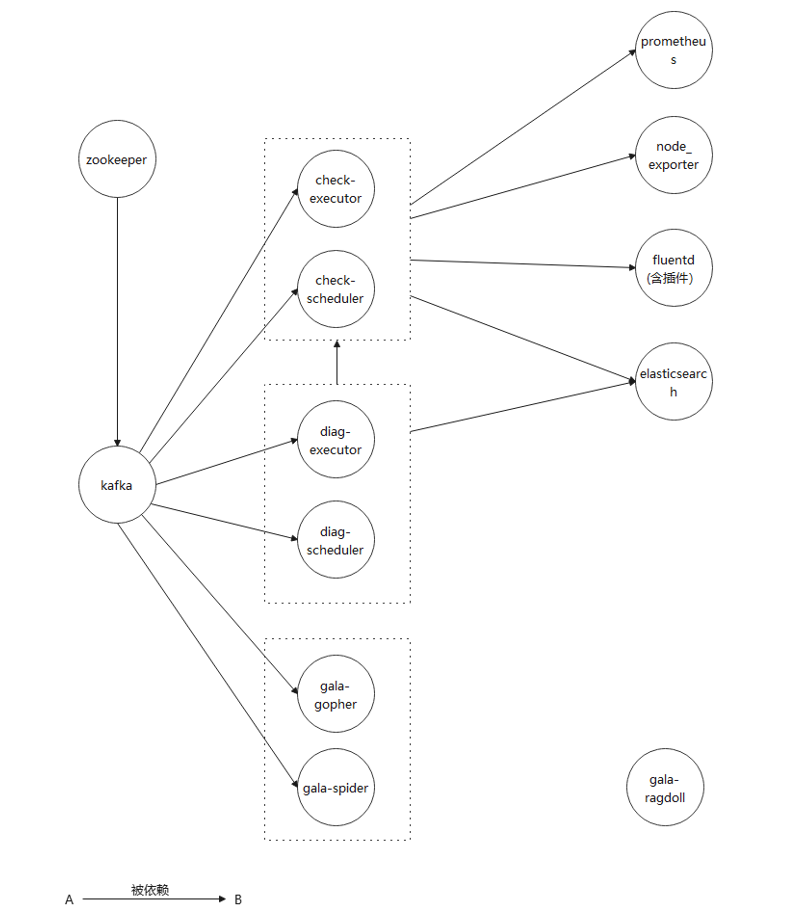
- 如图所示为默认提供的组件之前的依赖关系。服务正常运行需要提前安装好前置依赖。
- elasticsearch在aops框架安装时已经安装在主节点,如果没有组建集群的需要,修改配置即可使用,无需额外部署。
- aops框架中提供的其他组件未在图中具体列出。
2.1.3 默认任务配置
(1)zookeeper
zookeeper主要负责集群管理,并且是kafka运行的基础,需要配置在集群的每个节点中。
- 主机配置
主机清单中对集群中每个节点的IP、节点ID进行配置:
zookeeper_hosts:
hosts:
192.168.1.1: # 主机名
ansible_host: 192.168.1.1 # 主机IP
ansible_python_interpreter: /usr/bin/python3
myid: 2 # zookeeper节点ID
192.168.1.2:
ansible_host: 192.168.1.2
ansible_python_interpreter: /usr/bin/python3
myid: 1
192.168.1.3:
ansible_host: 192.168.1.3
ansible_python_interpreter: /usr/bin/python3
myid: 3
- 变量配置
zookeeper的变量包括:
---
# zookeeper user group 用户名、用户组
user: "zookeeper"
group: "zookeeper"
# zookeeper data path data路径
data_dir: "data"
# zookeeper log path 日志路径
zookeeper_log_path: "log"
# zookeeper install path 安装路径
install_dir: "/opt/zookeeper"
# zookeeper port config 端口配置
leader_port: 2888
vote_port: 3888
client_port: 2181
(2)kafka
主机配置
kafka 需要在安装zookeeper之后再安装。主机清单中需要配置kafka的端口、ID。同时需要配置zookeeper的IP与ID。
kafka_hosts:
hosts:
192.168.1.1: # 主机名
ansible_host: 192.168.1.1 # 主机IP
ansible_python_interpreter: /usr/bin/python3
kafka_id: 2 # kafka id
kafka_port: 9092 # kafka 监听端口
192.168.1.2:
ansible_host: 192.168.1.2
ansible_python_interpreter: /usr/bin/python3
kafka_id: 1
kafka_port: 9092
192.168.1.3:
ansible_host: 192.168.1.3
ansible_python_interpreter: /usr/bin/python3
kafka_id: 3
kafka_port: 9092
zookeeper_hosts: # zookeeper集群IP配置
hosts:
192.168.1.1: # 主机名
ansible_host: 192.168.1.1 # 主机IP
ansible_python_interpreter: /usr/bin/python3
myid: 2 # zookeeper id
192.168.1.2:
ansible_host: 192.168.1.2
ansible_python_interpreter: /usr/bin/python3
myid: 1
192.168.1.3:
ansible_host: 192.168.1.3
ansible_python_interpreter: /usr/bin/python3
myid: 3
- 变量配置
---
# zookeeper user group 用户、用户组
user: "kafka"
group: "kafka"
# Log Path 日志路径
kafka_log_path: "log"
# Install path 安装路径
install_dir: "/opt/kafka"
# zookeeper client port 客户端端口
zk_client_port: 2181
(3)prometheus
主机配置
prometheus负责集中采集的kpi数据项。只需要安装在server 节点上。另外,Prometheus需要去node_exporter上抓取数据,需要配置可连接的node_exporter的节点IP。
node_exporter_hosts:
hosts:
192.168.1.1:
ansible_host: 192.168.1.1
ansible_python_interpreter: /usr/bin/python3
192.168.1.2:
ansible_host: 192.168.1.2
ansible_python_interpreter: /usr/bin/python3
192.168.1.3:
ansible_host: 192.168.1.3
ansible_python_interpreter: /usr/bin/python3
prometheus_hosts:
hosts:
192.168.1.2:
ansible_host: 192.168.1.2
ansible_python_interpreter: /usr/bin/python3
- 变量配置
---
# prometheus 用户 用户组
user: "prometheus"
group: "prometheus"
# prometheus 监听端口
prometheus_listen_port: 9090
# node_exporter 监听端口
node_exporter_listen_port: 9100
# prometheus 配置文件路径
prometheus_conf_dir: "/etc/prometheus"
(4)node_exporter
- 主机配置
node_exporter需要安装在所有需要采集数据的主机节点上,主机需要配置IP。
node_exporter_hosts:
hosts:
192.168.1.1:
ansible_host: 192.168.1.1
ansible_python_interpreter: /usr/bin/python3
192.168.1.2:
ansible_host: 192.168.1.2
ansible_python_interpreter: /usr/bin/python3
192.168.1.3:
ansible_host: 192.168.1.3
ansible_python_interpreter: /usr/bin/python3
- 变量配置
---
# node_exporter user 用户 用户组
user: "node_exporter"
group: "node_exporter"
# Listening port 监听端口
node_exporter_listen_port: 9100
(5)MySQL
- 主机配置
MySQL数据库只需要安装在server 节点上。
mysql_hosts:
hosts:
192.168.1.2:
ansible_host: 192.168.1.2
ansible_python_interpreter: /usr/bin/python3
- 变量配置
---
# mysql 用户、用户组
user: "mysql"
group: "mysql"
(6)elasticsearch
- 主机配置
elasticsearch数据库只需要安装在server 节点上。需要配置server节点上,并指定节点ID。如果需要配置分布式集群,需要修改主机清单和配置文件elasticsearch.j2。
elasticsearch_hosts:
hosts:
192.168.1.2:
ansible_host: 192.168.1.2
ansible_python_interpreter: /usr/bin/python3
elasticsearch_id: elasticsearch_node1
- 变量配置
---
# elasticsearch User Group 用户 用户组
user: elasticsearch
group: elasticsearch
# elasticsearch repo config 官方repo源配置
repo_name: "Elasticsearch"
repo_description: "Elasticsearch repository for 7.x packages"
repo_base_url: "https://artifacts.elastic.co/packages/7.x/yum"
repo_gpgkey: "https://artifacts.elastic.co/GPG-KEY-elasticsearch"
repo_file: "elasticsearch"
# elasticsearch Install dir 安装目录
install_dir: /etc/elasticsearch/
# elasticsearch cluster name 集群名称
elasticsearch_cluster_name: myApp
# elasticsearch init master ip address 默认的集群主节点IP
elasticsearch_cluster_init_master: 192.168.1.2
# elasticsearch listen port 监听端口
elasticsearch_listen_port: 9200
# elasticsearch data path 数据目录
elasticsearch_data_path: "/var/lib/elasticsearch"
# elasticsearch log path 日志目录
elasticsearch_log_path: "/var/log/elasticsearch"
# elasticsearch network host 网络IP
elasticsearch_network_host: "{{elasticsearch_cluster_init_master}}"
(7)fluentd
- 主机配置
fluentd 负责日志采集,部署在所有需要采集的节点上,最终将日志汇总在elasticsearch上。
fluentd_hosts:
hosts:
192.168.1.1: # 主机名
ansible_python_interpreter: /usr/bin/python3
elasticsearch_host: 192.168.1.1 # elasticsearch监听的IP
192.168.1.2:
ansible_python_interpreter: /usr/bin/python3
elasticsearch_host: 192.168.1.1 # elasticsearch监听的IP
192.168.1.3:
ansible_python_interpreter: /usr/bin/python3
elasticsearch_host: 192.168.1.1 # elasticsearch监听的IP
- 变量配置
---
# fluentd config path
fluentd_config_dir: /etc/fluentd/
# 修改history记录的脚本
change_history_format: true
change_history_format_scripts:
- zzz_openEuler_history.csh
- zzz_openEuler_history.sh
# 修改demsg记录的脚本
change_dmesg_format: true
change_dmesg_format_scripts: fluentd_dmesg.sh
# demsg端口
fluentd_demsg_port: 61122
(8) adoctor-check-executor与adoctor-check-scheduler
- 主机配置
adoctor-check-executor与adoctor-check-scheduler依赖于aops框架运行,默认都部署在主节点上。executor与scheduler之间通过kafka进行通信。
adoctor-check-executor主机清单配置:
adoctor_check_executor_hosts:
hosts:
192.168.1.1: # 主机名
ansible_host: 192.168.1.1 # 主机IP
ansible_python_interpreter: /usr/bin/python3
adoctor-check-scheduler主机清单配置:
adoctor_check_scheduler_hosts:
hosts:
192.168.1.1: # 主机名
ansible_host: 192.168.1.1 # 主机IP
ansible_python_interpreter: /usr/bin/python3
- 变量配置
adoctor-check-executor变量配置:
# check executor的配置文件目录
check_executor_conf_dir: "/etc/aops"
# check executor连接的kafka服务器列表host:port。ip默认为当前主机IP,port默认为9092
kafka_server_list: 192.168.1.1:9092
adoctor-check-scheduler变量配置:
# check scheduler的配置文件目录
check_scheduler_conf_dir: "/etc/aops"
# check scheduler连接的kafka服务器列表host:port。ip默认为当前主机IP,port默认为9092
kafka_server_list: 90.90.64.64:9092
# check scheduler服务监听的端口,默认为11112
check_scheduler_port: 11112
(9)adoctor-diag-scheduler与adoctor-diag-executor
- 主机配置
adoctor-diag-executor与adoctor-diag-scheduler依赖于aops框架运行,默认都部署在主节点上。executor与scheduler之间通过kafka进行通信。
adoctor-diag-executor主机清单配置:
adoctor_diag_executor_hosts:
hosts:
192.168.1.1: # 主机名
ansible_host: 192.168.1.1 # 主机IP
ansible_python_interpreter: /usr/bin/python3
adoctor-diag-scheduler主机清单配置:
adoctor_diag_scheduler_hosts:
hosts:
192.168.1.1: # 主机名
ansible_host: 192.168.1.1 # 主机IP
ansible_python_interpreter: /usr/bin/python3
- 变量配置
adoctor-diag-executor变量配置:
# diag executor的配置文件目录
diag_executor_conf_dir: "/etc/aops"
# diag executor连接的kafka服务器列表host:port。ip默认为当前主机IP,port默认为9092
kafka_server_list: 192.168.1.1:9092
adoctor-diag-scheduler变量配置:
# diag scheduler的配置文件目录
diag_scheduler_conf_dir: "/etc/aops"
# diag scheduler连接的kafka服务器列表host:port。ip默认为当前主机IP,port默认为9092
kafka_server_list: 192.168.1.1:9092
# diag scheduler服务监听的端口,默认为11113
diag_scheduler_port: 11113
(10)gala-ragdoll
- 主机配置
gala-ragdoll为配置溯源模块的主要组件,部署在主节点上。
gala_ragdoll_hosts:
hosts:
192.168.1.1: # 主机名
ansible_host: 192.168.1.1 # 主机IP
ansible_python_interpreter: /usr/bin/python3
- 变量配置
---
# gala-ragdoll服务监听的端口
gala_ragdoll_port: 11114
(11)gala-gopher与gala-spider
- 主机配置
gala-gopher与gala-spider是架构感知模块的主要组件,其中gala-gopher部署在各个远程主机上,进行信息收集,通过kafka将消息推送到主节点的gala-spider上。gala-spider部署在主节点上,对收集到的数据进行分析。
gala-gopher主机清单配置:
gala_gopher_hosts:
hosts:
192.168.1.1: # 主机名
ansible_host: 192.168.1.1 # 主机IP
ansible_python_interpreter: /usr/bin/python3
192.168.1.2:
ansible_host: 192.168.1.2
ansible_python_interpreter: /usr/bin/python3
192.168.1.3:
ansible_host: 192.168.1.3
ansible_python_interpreter: /usr/bin/python3
gala-spider主机清单配置:
gala_spider_hosts:
hosts:
192.168.1.1: # 主机名
ansible_host: 192.168.1.1 # 主机IP
ansible_python_interpreter: /usr/bin/python3
- 变量配置
gala-gopher变量配置:
---
# gala gopher安装目录
install_dir: "/opt/gala-gopher/"
# gala-gopher连接的kafka host,需要配置为管理节点的主机IP
gala_gopher_kafka_host: 192.168.1.1
# gala-gopher监听的kafka port
gala_gopher_listening_kafka_port: 9092
# gala-gopher探针配置
probes_example_switch: "off"
probes_system_meminfo: "off"
probes_system_vmstat: "off"
probes_system_tcp: "off"
probes_system_inode: "off"
extend_probes_redis: "off"
gala-spider变量配置:
---
# log path
log_path: "/var/log/spider"
# install path
install_dir: "/opt/spider/"
# kafka host 默认配置为主机IP
gala_spider_kafka_host: 192.168.1.1
# Listening port
gala_spider_listening_kafka_port: 9092
# excluded addr
exclude_addr: ["192.168.x.x"]
# basic table name, please don't delete originally contains in the list. And append items in order if necessary:
base_table_name: ["tcp_link", "lvs_link"]
other_table_name: ["nginx_statistic" , "lvs_link" , "haproxy_link" , "dnsmasq_link"]
# gala-spider listening port
gala_spider_port: 11115
3 执行部署任务
3.1 修改默认配置
首先task query 查询默认任务id,注意默认任务的主机必须已经被正确添加。
默认任务配置:/etc/aops/default.json。参照Aops框架使用手册章节4配置参数。若已配置,此步骤可忽略。
vim /etc/aops/default.json
- 修改/etc/ansible/ansible.cfg , 需要取消对配置项host_key_checking 的注释。
vim /etc/ansible/ansible.cfg
# uncomment this to disable SSH key host checking
host_key_checking = False
3.2 任务组件步骤配置
一个任务由多个步骤组成,基本可以认为每个步骤会安装一个组件,按照步骤组合的先后顺序,可以最终完成一次任务。修改任务的步骤,需要修改tasks/任务名.yml,格式如下:
---
step_list: # 步骤列表
zookeeper: # 第一步安装kafka,可以使用默认模板
enable: true # 置为false则跳过安装步骤,true执行安装步骤
continue: false # 置为false则安装失败时终止任务,true执行安装失败时继续下一个组件安装
kafka:
enable: false
continue: false
prometheus:
enable: false
continue: false
node_exporter:
enable: false
continue: false
mysql:
enable: false
continue: false
elasticsearch:
enable: false
continue: false
fluentd:
enable: false
continue: false
adoctor_check_executor:
enable: false
continue: false
adoctor_check_scheduler:
enable: false
continue: false
adoctor_diag_executor:
enable: false
continue: false
adoctor_diag_scheduler:
enable: false
continue: false
gala_gopher:
enable: false
continue: false
gala_spider:
enable: false
continue: false
gala_ragdoll:
enable: false
continue: false
3.3 组件部署选项配置
组件的playbook中会定义几个关键选项的配置,如下:
---
- hosts: example_hosts # 此处需套填写所安装组件配置的主机名。(建议按照统一生成的名称来处理)
gather_facts: no
user: root
vars_files: # 需要引用变量文件时,加入vars文件
- "../vars/example_vars.yml"
vars: # 定义安装步骤的变量,在安装过程中可以根据需要修改是否启用
install_example: true # 安装 example
config_example: true # 配置 example
start_example: true # 启动 example service
create_user: true # 创建新的用户和组
roles: # playbook中需要完成的角色剧本,可自定义,与顺序相关
- ../roles/user # (1)创建用户 playbook
- ../roles/example # (2) 安装 exampl playbook
3.4 认证
account certificate : key 必须是添加主机时使用的key , 每次重启manager后必须重新执行certificate。
ps certificate --key xxxx --access_token xxxx
3.5 执行部署任务
命令行执行:
xxxxxxxxxx aops task --action execute --task_list 95c3e692ff3811ebbcd3a89d3a259eef --access_token xxx
或网页执行:
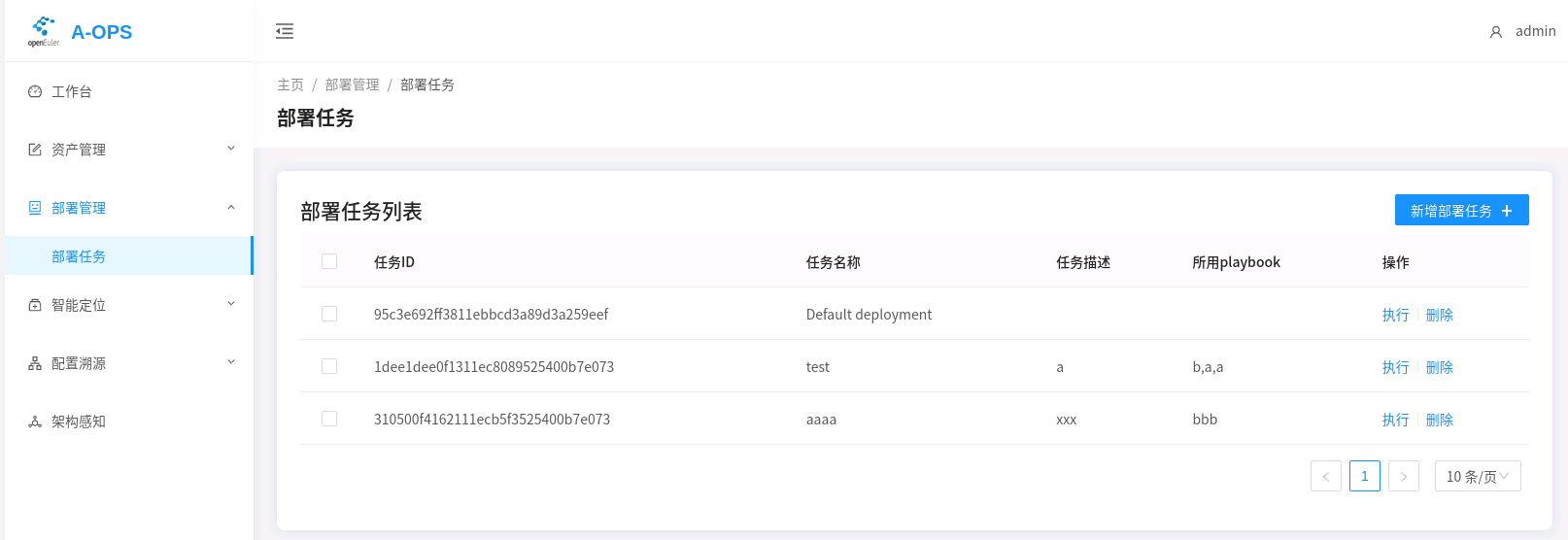
在部署任务页面,根据要执行的任务ID,点击执行按钮。当前此功能会直接返回成功,执行进度与详细结果可以在/var/log/aops/manager.log中查看。





