1 CFGO反馈优化
1.1 特性描述
- 概念:CFGO (Continuous Feature Guided Optimization)是多模态(源代码、二进制)、全生命周期(编译、链接、链接后、运行时、OS、库)的持续反馈优化。
- 核心思想:在保证程序功能不变的前提下,通过收集程序运行时信息,指导各种编译优化技术进行更准确的,获得性能更优的目标程序。
- 主要优化点:
- 代码布局优化:通过基本块重排、函数重排、冷热分区等技术,优化目标程序的二进制布局,提升i-cache和i-TLB命中率。
- 高级编译器优化:内联、循环展开、向量化、间接调用等提升编译优化技术受益于反馈信息,能够使编译器执行更精确的优化决策。
1.2 BOLTUSE
1.2.1 选项介绍
选项-fbolt-use
此选项用于直接使用指定的BOLT profile完成链接后优化。使用时需要提前准备好BOLT优化所需要的profile文件,可以使用AutoBOLT模式获取,也可以使用perf采样并执行perf2bolt转换生成。
1.2.2 常见应用使能方式
Mysql
bashcmake .. -DCMAKE_INSTALL_PREFIX=/home/install/mysql-8.0.25 -DBUILD_CONFIG=mysql_release -DWITH_BOOST=../boost -DCMAKE_C_FLAGS="-Wl,-q" -DCMAKE_CXX_FLAGS="-Wl,-q" -DCMAKE_C_LINK_FLAGS="-Wl,-q" -DCMAKE_CXX_LINK_FLAGS="-Wl,-q -fbolt-use=/path/to/mysqld.profile -fbolt-target=mysqld" -DCMAKE_EXE_LINKER_FLAGS="-Wl,-q"MongoDB
bash# 带重定位信息的基线版本构建 python3 buildscripts/scons.py MONGO_VERSION=6.1.0 DESTDIR=/usr/local/mongo install-all-meta CFLAGS="-march=armv8-a+crc -mtune=generic -Wl,-q" CXXFLAGS="-march=armv8-a+crc -mtune=generic -Wl,-q" LINKFLAGS="-Wl,-q" -j 128 --disable-warnings-as-errors # perf采样 + perf2bolt生成bolt profile # 使用boltuse构建优化版本,注意如果使用的llvm-bolt版本不支持pie,需要手动在SConstruct中删掉pie选项 python3 buildscripts/scons.py MONGO_VERSION=6.1.0 DESTDIR=/usr/local/mongo install-devcore CFLAGS="-march=armv8-a+crc -mtune=generic -Wl,-q" CXXFLAGS="-march=armv8-a+crc -mtune=generic -Wl,-q" LINKFLAGS="-Wl,-q -fbolt-use=./mongod.profile -fbolt-target=mongod" -j 128 --disable-warnings-as-errorsRedis
bashmake CFLAGS="-Wl,-q" LDFLAGS="-fbolt-use=/path/to/redis.profile -fbolt-target=redis-server"说明
- 默认使用当前路径下文件名为data.fdata的profile完成优化,可以使用-fbolt-use=FILE指定使用的profile,如-fbolt-use=/tmp/a.fdata。
- 可以和-fbolt-target、-fbolt-option=<options>共用。
1.3 AutoBOLT
1.3.1 选项介绍
插桩反馈优化场景下,需要经过两次编译,第一次带编译选项-fprofile-generate[=path],经过一系列典型场景测试后生成profile数据,第二次带编译选项-fprofile-use[=path]编译优化版本,AutoBOLT会将插桩数据转换成BOLT profile,并自动使能链接后优化。
适用场景
不介意插桩阶段性能损耗,对构建和测试时间不敏感,追求极致性能等情况
使用方式
# 插桩,生成gcno
gcc -O3 -fprofile-generate[=path] -fprofile-update=atomic -o test test.c
# 执行测试,获得gcda./test# 使用生成的gcda数据编译生成新的可执行文件
gcc -O3 -fprofile-use[=path] -fprofile-correction -Wno-error=coverage-mismatch -Wno-error=missing-profile -fauto-bolt -fbolt-target=test_pgoed -o test_pgoed test.c1.3.2 自动(采样)反馈优化场景
与插桩式反馈优化不同,自动反馈优化使用perf收集程序的运行信息,然后使用create_gcov工具解析来自perf的采样信息为编译器所需profile,最后使用选项-fauto-profile读取profile完成优化。选项-fprofile-correction用于使能mcf算法,平滑由于采样导致的基本块计数不均衡。
适用场景
频繁发布版本,需要在生产环境部署整套系统等情况。
使用方式
# 编译带调试信息的可执行文件
gcc -O3 -g -o test_prof test.c
# 使用perf采集性能数据
perf record -e br_retired -- ./test_prof
# 使用create_gcov将perf.data解析为gcov文件
create_gcov --binary=./test_prof --profile=perf.data --gcov=test.gcov -gcov_version=2
# 利用gcov性能数据编译生成新的可执行文件
gcc -O3 -fauto-profile=test.gcov test.c -o test_autofdo补充说明
- 转换后的profile默认保存在当前路径,可以使用-fauto-bolt=PATH指定BOLT profile的保存路径,如-fauto-bolt=/tmp。
- 当前插桩反馈优化在内核反馈优化的场景下,支持使用gcov-tool工具合并插桩反馈优化文件以生成对多种场景具有性能提升的高性能内核。
- 使用插桩反馈优化技术优化多线程应用场景下使用-fprofile-generate[=path]时可以加上-fprofile-update=atomic,可以生成更精准的数据。
- 使用插桩反馈优化技术优化应用的场景,使用-fprofile-correction可以自动修正部分profile数据,使用-Wno-error=coverage-mismatch -Wno-error=missing-profile可以屏蔽profile无法对应或不存在的情况下的报错。
典型应用使能方式
MySQL/RocksDB等通过Cmake构建的应用
bash# 带重定位信息的基线版本构建 cmake .. -DCMAKE_INSTALL_PREFIX=/usr/local/mysql -DBUILD_CONFIG=mysql_release -DWITH_BOOST=../boost -DCMAKE_C_FLAGS="-Wl,-q" -DCMAKE_CXX_FLAGS="-Wl,-q" -DCMAKE_C_LINK_FLAGS="-Wl,-q" -DCMAKE_CXX_LINK_FLAGS="-Wl,-q" -DCMAKE_EXE_LINKER_FLAGS="-Wl,-q" # 使用autobolt构建优化版本Redis/Memcached等通过Make构建的应用
bash# 带重定位信息的基线版本构建 make CFLAGS="-Wl,-q" CXXFLAGS="-Wl,-q" # 优化版本构建 make CFLAGS="-fprofile-use=./profile -fauto-bolt -fbolt-target=redis-server -Wl,-q -Wno-missing-profile" LDFLAGS="-Wl,-q"
典型应用效果
| MySQL | openGauss | Nginx | Ceph | Redis | kernel |
|---|---|---|---|---|---|
| +15% | +5% | +15% | +7% | +5% | +5% |
常见使用问题
- 使用-fauto-bolt和-fbolt-target时出现打印信息: The linker[2] is not for exec, just skip.22.03sp3,之前的gcc版本不支持对pie或so优化,可以使用sp4及之后版本。
AutoBOLT和BOLTUSE的通用选项
- -fbolt-target=NAME用于指定BOLT的优化对象,使用该选项后除了NAME之外的二进制和动态库都不会优化。使用该选项,必须指定NAME。
- -fbolt-option=PARAM用于指定BOLT的优化选项,不同选项以逗号分隔,如-fbolt-option="-reorder-blocks=cache+,-reorder-functions=hfsort+"。使用该选项,必须指定PARAM,优化选项详情可使用llvm-bolt --help查询。
1.4 PGO
特性说明
该优化通过插桩形式收集程序运行时信息(profile)进行优化决策,编译器更换这些运行时信息知道各种编译优化以进行更准确的优化决策,生成目标程序。
该有化主要包括两种优化方式:
- Edge Profile:在函数CFG(Control Flow Graph)的边上插入计数器,获取程序的运行计数信息。
- Value Profile:由于编译器的优化编希望知道一些表达式变量的取值,该优化在插桩过程中插入代码统计表达式变量经常的取值。程序运行后,将profile文件读回编译器,指导对应的优化编执行更佳的优化决策。当前GCC支持多种value profile计数功能,包括变量常用取值、是否是2的幂次、经常的间接调用地址、函数首次运行编号等。
1.4.1 选项介绍
选项-fprofile-generate[=path]
此选项打开了-fprofile-arcs和-fprofile-values。-fprofile-generate可以传入参数path,用来指定profile反馈数据文件的存储文件,同-fprofile-dir。
选项-fprofile-correction
此选项会使用启发性纠错或者平滑得中和profile反馈数据不一致的情况。
选项-Wno-coverage-mismatch
缺省情况下,当profile不匹配源代码时会被作为错误处理。此选项可以用来将错误转换为警告,仅建议在较少改动并且改动部分为冷代码的情况下适用。
选项-fprofile-use[=path]
此选项适用存储在path下的profile指导编译器进行优化。
1.4.2 内核反馈优化
背景
当今大多数服务器只运行单个或少数的特定应用,因此根据特定的运行程序对操作系统进行优化,将获得更多的性能收益。
DEMO
下载内核源码。
bashyum install -y kernel-source编译插装代码。
进入内核源码目录,进行内核选项配置,这里以openEuler 5.10内核为例。
bashcd /usr/src/linux-5.10.0*** make openeuler_defconfig make menuconfig 在菜单中,进入General setup,选择Local Version-append to kernel release,填入合适的后缀名,例如-test-going双击esc回到上一级目录,进入General architecture-dependent options > GCOV-based kernel profiling,双击esc回到主目录,进入kernel hacking > Compile-time checks and compiler options profiling,关闭Compile the kernel debug,保存并退出。编译rpm包(96可替换为机器最大核数)。
bashmake binrpm-pkg -j 96使用插桩内核。
在服务器端安装插桩内核,设置为默认内核并重启。
bashrpm -ivh kernel*** --forcegrub2-set-default 0 reboot执行目标优化的应用测试,这里以Nginx的wrk测试套为例。
在服务器端开Nginx 服务器。
bashnginx -c nginx.conf在客户端运行Nginx wrk测试套。
bashwrk -c 2000 -d 60s -t 20 --latency --timeout 5s -H "Connection: close" http://192.168.1.10:10000/index.html执行profile收集脚本,将profile信息从内存写入磁盘中。
(可选)如果需要针对多个应用编译优化内核,可以尝试合并多个应用的profile,这里以应用A和应用B为例。
bashgcov-tool merge a/gcovdata b/gcovdata编译优化后的内核,进入内核源码目录,进行内核选项配置。
bashmake openeuler_defconfig make menuconfig 在菜单中,进入General Setup.选在Local version-append to kernel release,填写合适的后缀名,例如-test-pgoed,双击回到主目录,关闭Compile the kernel with debug info,保存并退出。编译rpm包(96可替换为机器最大核数)。
bashmake binrpm-pkg -j 96 KCFLAGS="-fprofile-use -fprofile-correction -Wno-error=coverage-mismatch -Wno-error=missing-profile -fprofile-dir=gcovdata"
常见使用问题
须知
Profile 文件没有正常生成
- 可能原因一:于-fprofile-generate生成profile的目录下没有写入权限。可以使用chmod 777 [生成目录的绝对路径方式]解决。
- 可能原因二:程序没有正常退出。在应用退出时会调用**__gcov_exit()**刷新profile信息。可以使用gdb attach 应用,手动调用__gcov_exit()解决。
1.5 LTO
1.5.1 特性介绍
背景
在传统编译流程中,gcc 将单个源文件(称谓一个编译单元)直接进行编译优化生成包含汇编代码的.o目标对象文件,并由链接器对这些.o文件进行符号表解析与重定位,链接成可执行文件。在这个过程中,拥有跨文件函数调用信息的链接器由于操作的是汇编代码,难以进行编译优化,而可以执行编译优化的环节,却没有跨文件的全局信息。这样的编译框架,虽然提高了编译效率,每次重新编译只需要编译修改过的少量编译单元,但也丢失了许多跨文件的优化机会。
LTO流程
LTO 设计的初衷就是希望能够在链接时,拥有跨编译单元的调用信息的时候,进行编译优化,提供更多的优化机会。为了达到这个目的,LTO 需要将编译优化所需的 IR 信息保留到链接时。在链接时,链接器会调用 LTO 插件,执行全程序分析,生成更加有效的优化决策,再经由编译优化生成更高效的IR,进一步转成包含汇编代码的目标对象文件,最后由链接器完成常规的链接工作。
分区与并行
由于需要处理全局的调用图,在执行LTO时往往需要更长的编译时间,有些时候,LTO的编译时间会达到非LTO的数倍。为了使 LTO 能够并行,以加快编译速度,分区模式出现了。在分区模式下,全局调用图会根据模块之间的关联性被拆分成若干个分区,各分区之间独立并行优化,是一种在编译时间和优化效果之间的平衡。
1.5.2 使用方式
选项-flto=
编译选项中加入此选项开启LTO。可通过-flto=n指定LTO的并发数,如使用auto可以指定与GNU make一致(如果可以获取)或是与当前机器线程数一致的并发数。
选项-ffat-lto-objects
该选项将生成同时包含汇编信息和LTO信息的目标文件。并且在-ffat-lto-objects开启的情况下,允许通过-fno-lto选项,使用目标对象文件的汇编信息,来完成常规的链接,而不执行链接时优化。
选项-flto-partion=1to1|balanced|max|one|none
该选项可以通过引入不同的分区策略从而加快编译速度。1to1意味着分区与源文件一一对应;balanced控制每个分区在规模上相等;max会为每一个符号创建一个分区;one会尽量生成一个分区;none会直接调过全程序分以及分区的环节。
选项-flto-compresson-level=n
该选项用以控制LTO对性文件中IR信息的压缩等级。
DEMO
// four.cint four() { return 4;}
// five.cint five() { return 5;}
// test.cextern int four();extern int five();int main() { return four() + five();}
gcc -O2 -flto test.c four.c five.c
# 或者
gcc -O2 -flto -c test.cgcc -O2 -flto -c four.cgcc -O2 -flto -c five.cgcc test.o four.o five.o说明
对于上面这个案例,在使用 LTO 生成的可执行文件中,four() + five()会被内敛+常量折叠优化为立即数9,省略了函数调用与计算的步骤,这在非 LTO 模式下是无法实现的。 如果仅对four.c和test.c生成了 LTO 对象文件,最终结果便成了4 + five(),仅部分lto对象文件参与了局部范围内的链接时优化。
1.5.3 常见使用问题
plugin needed to handle lto object
链接器或者相关工具链在处理 lto 对象文件时,需要调用 lto 插件来解析对应 section 的信息。这类报错一般是由于 ar/ranlib/nm 没有调用 lto 插件导致的,可以通过更换为 gcc-ar/gcc-ranlib/gcc-nm 来解决。
undefined symbol
这类问题有许多个比较原因,以下举例比较常见的三种:
一是符号版本控制相关的情况。由于 gcc 不支持 asm 形式的符号版本控制,需要在应用源码层面替换为__attribute__(.symver) 形式的符号版本控制。
二是由于编译过程依赖了 objcopy 等工具,此类工具不支持处理lto对象文件,会导致需要重命名重定义的符号没有重命名,引起符号未定义的问题。
三是涉及到了链接时插桩(-Wl,--wrap=foo),在lto下会出现 __wrap_foo 的符号未定义的问题,该问题上游社区正在解决中。
multi-defined symbol
一般是由于编译过程依赖了 objcopy 等工具,此类工具不支持处理lto对象文件,会导致需要隐藏的符号没有隐藏,引起重复定义的问题。
1.6 静态编译
1.6.1 选项 -fipa-struct-reorg
内存空间布局优化,将结构体成员在内存中的排布进行新的排列组合,来提高cache的命中率。
结构体拆分:将结构体的冷热成员单独拆分成一个结构体类型
图1 结构体拆分优化原理示意图
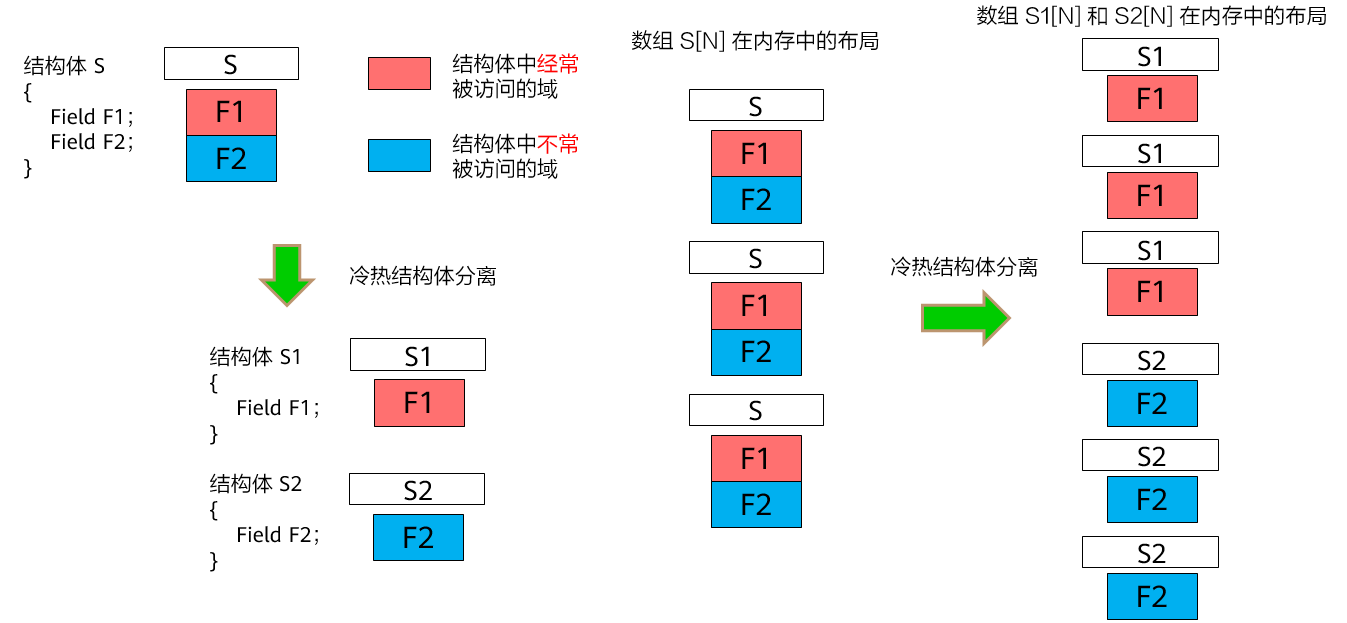
将以下结构体:
bashstruct S { type1 field1; // Hot field type2 field2; };S *v;转化为:
bashstruct S_hot { type1 field1; }; struct S_cold { type2 field2; }; S_hot *v_hot; S_cold *v_cold;结构体数组优化:将结构体的数组转化为数组的结构体。
图1 结构体数组优化原理示意图
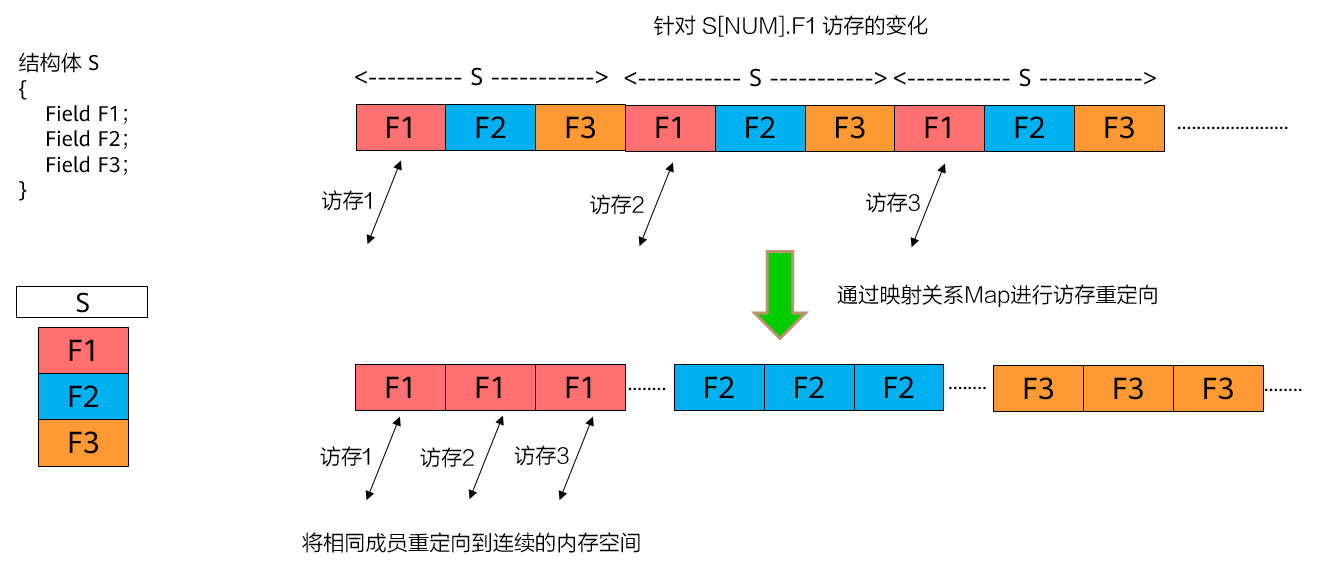
将以下结构体:
bashstruct { type1 field1; type2 field2; type3 field3; } arr[N];转化为:
bashstruct { type1 field1[N]; type2 field2[N]; type3 field3[N]; } arr;
使用方法
在编译选项中加入:
-O3 -flto -flto-partition=one -fipa-struct-reorg须知
-fipa-struct-reorg选项,需要在-O3 -flto -flto-partition=one全局同时开启的基础上才使能。
SPEC性能提升效果:SPECCPU2017 intrate 505.mcf子项性能提升20%。
1.6.2 选项 -fipa-reorder-fields
内存空间布局优化之结构体重排优化,根据结构体中成员的占用空间大小,将成员从大到小排列,以减少边界对齐引入的padding,来减少结构体整体占用的内存大小,以提高cache的命中率。 将以下结构体
struct S
{
double a;
int b;double c;
double d;
short e;
double f;
double g;
double h;
double i;
};经过重排后转化为:
struct S.reorder
{
double a;
double i;
double c;
double d;
double f;
double g;
double h;
int b;
short e;
}适用方法
在选项中加入-O3 -flto -flto-partition=one -fipa-reorder-fields须知
-fipa-reorder-fields选项,需要在-O3 -flto -flto-partition=one全局同时开启的基础上才使能。
SPEC性能提升效果:SPECCPU2017 intrate 505.mcf子项性能提升20%。
1.6.3 选项 -fipa-struct-reorg=n
使用该选项控制内存空间布局优化系列优化。
-fipa-struct-reorg=0 不启用任何优化。
-fipa-struct-reorg=1 启用结构体拆分和结构体数组优化,等同使用-fipa-struct-reorg
-fipa-struct-reorg=2 在 -fipa-struct-reorg=1 的基础上,新增结构体成员重排-fipa-reorder-fields
-fipa-struct-reorg=3 在-fipa-struct-reorg=2 的基础上,新增结构体冗余成员消除优化。结构体冗余成员消除,消除结构体中从不读取的结构体成员,同时删除冗余的写语句。 将以下结构体:
bashstruct S { type1 field1; // Never read in whole program type2 field2;};转化为
bashstruct S.layout { type2 field2; };-fipa-struct-reorg=4 在-fipa-struct-reorg=3的基础上,新增安全结构体指针压缩优化。
结构体指针压缩将结构体域成员中的结构体指针压缩至可选的8、16和32 bits,缩小结构体占用内存大小,降低从内存中读写数据时的带宽压力,从而提升性能。
- 安全的结构体指针压缩仅支持结构体数组大小在编译期间已知的场景。
- 使用--param compressed-pointer-size=[8,16,32]控制压缩目标大小,默认取值为32。
将以下结构体:
bashstruct S { struct S* field1; type2 field2; };转化为:
bashstruct S.layout { uint32_t field1.pc; type2 field2; };-fipa-struct-reorg=5 在-fipa-struct-reorg=4的基础上,放宽了结构体指针压缩优化的应用场景。
该等级支持结构体数组大小在编译期间未知的场景,用户需自行确认压缩等级合法,不同等级支持的最大结构体数组大小如下表所示。
指针大小 最大支持数组范围 8 254(0xff-1) 16 65534(0xffff-1) 32 4294967294(0xffffffff-1) -fipa-struct-reorg=6 在-fipa-struct-reorg=5的基础上,新增结构体数组semi-relayout优化。*
semi-relayout在一定范围内,将结构体数组中各结构体的成员打包后重排,提高数据空间局部性,从而提升性能。
通过参数--param semi-relayout-level=[11,12,13,14,15]控制semi-relayout的重排规模,默认值为13,即semi-relayout将每1024个结构体作为一组进行重排,不足1024的情况下以padding的形式补齐1024个结构体空间;计算方式:(1 << semi-relayout-level) / 8。
将以下结构体数组在内存中的排布形式从连续的结构体按照如下图形式转换。
图1 semi-relayout优化原理示意图
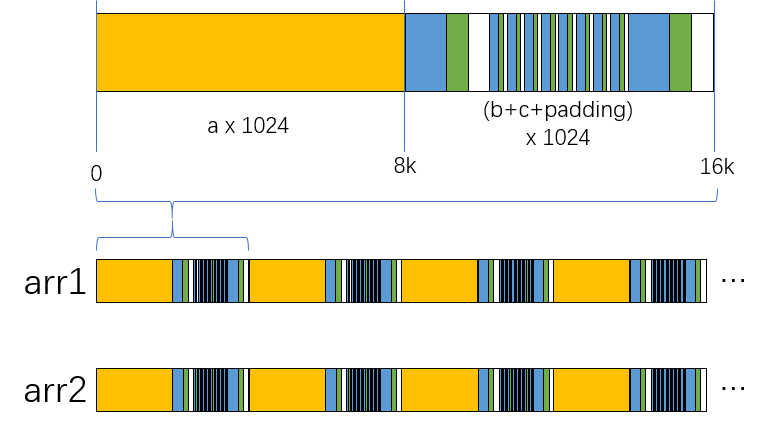 bash
bashstruct S { long a, int b, short c };
使用方法
在选项中加入:
-O3 -flto -flto-partition=one -fipa-struct-reorg=n其中n取值范围为[0,6]。
须知
-fipa-struct-reorg=n选项,需要在-O3 -flto -flto-partition=one全局同时开启的基础上才使能。
1.6.4 选项 -ftree-slp-transpose-vectorize
该选项在循环拆分阶段,增强对存在连续访存读的循环的数据流分析能力,通过插入临时数组拆分循环;SLP矢量化阶段,新增对grouped_stores进行转置的SLP分析。
int foo (unsigned char *oxa, int ia, unsigned char *oxb, int ib)
{
unsigned tmp[4][4];
unsigned a0, a1, a2, a3;int sum = 0;
for (int i = 0; i < 4; i++, oxa += ia, oxb += ib)
{
a0 = (oxa[0] - oxb[0]) + ((oxa[4] - oxb[4]) << 16);
a1 = (oxa[1] - oxb[1]) + ((oxa[5] - oxb[5]) << 16);
a2 = (oxa[2] - oxb[2]) + ((oxa[6] - oxb[6]) << 16);
a3 = (oxa[3] - oxb[3]) + ((oxa[7] - oxb[7]) << 16);
int t0 = a0 + a1;int t1 = a0 - a1;int t2 = a2 + a3;
int t3 = a2 - a3;tmp[i][0] = t0 + t2;
tmp[i][2] = t0 - t2;tmp[i][1] = t1 + t3;
tmp[i][3] = t1 - t3;
}
for (int i = 0; i < 4; i++)
{
int t0 = tmp[0][i] + tmp[1][i];
int t1 = tmp[0][i] - tmp[1][i];
int t2 = tmp[2][i] + tmp[3][i];
int t3 = tmp[2][i] - tmp[3][i];
a0 = t0 + t2;
a2 = t0 - t2;
a1 = t1 + t3;
a3 = t1 - t3;
sum += a0 + a1 + a2 + a3;
}
return sum;
}对于如上所示的用例,针对第一个for循环,可以拆分为如下形式
for (int i = 0; i < 4; i++, oxa += ia, oxb += ib)
{
a00[i] = (oxa[0] - oxb[0]) + ((oxa[4] - oxb[4]) << 16);
a11[i] = (oxa[1] - oxb[1]) + ((oxa[5] - oxb[5]) << 16);
a22[i] = (oxa[2] - oxb[2]) + ((oxa[6] - oxb[6]) << 16);
a33[i] = (oxa[3] - oxb[3]) + ((oxa[7] - oxb[7]) << 16);
}
for (int i = 0; i < 4; i++)
{
int t0 = a00[i] + a11[i];
int t1 = a00[i] - a11[i];
int t2 = a22[i] + a33[i];
int t3 = a22[i] - a33[i];
tmp[i][0] = t0 + t2;
tmp[i][2] = t0 - t2;
tmp[i][1] = t1 + t3;
tmp[i][3] = t1 - t3;
}再针对于拆分所得的第一个循环,等号右边的计算同构且为连续load可以矢量化,但是由于左边a00[i]、a11[i]、a22[i]、a33[i]的内存地址不连续,无法作为矢量化SLP树的根节点,因此失去这种场景的矢量化机会。 在a00[i]、a11[i]、a22[i]、a33[i]写入内存时,期望寄存器中的内容为:
| register | values |
|---|---|
| vec0 | a00[0] a00[1] a00[2] a00[3] |
| vec1 | a11[0] a11[1] a11[2] a11[3] |
| vec2 | a22[0] a22[1] a22[2] a22[3] |
| vec3 | a33[0] a33[1] a33[2] a33[3] |
而每次迭代内可以计算得到寄存器的内容为:
| register | values |
|---|---|
| vec0 | a00[0] a11[0] a22[0] a33[0] |
| vec1 | a00[1] a11[1] a22[1] a33[1] |
| vec2 | a00[2] a11[2] a22[2] a33[2] |
| vec3 | a00[3] a11[3] a22[3] a33[3] |
将grouped_store进行转置,即可得到预期的SLP树根节点。再利用SLP原有的能力,进行后续的矢量化分析。
此外,针对拆分所得的第二个循环以及示例中的最后一个循环,tmp二维数组存在写入内存后立刻读取的行为,针对这种场景,将访存行为优化为寄存器之间的permutation行为。该访存优化默认开启。
使用方法
在选项中加入:
-O3 -ftree-slp-transpose-vectorize须知
-ftree-slp-transpose-vectorize选项,需要在-O3开启的基础上才使能。
1.6.5 选项 -fccmp2
该选项是Arm相关指令优化:增强ccmp指令使用场景,简化指令流水
针对如下代码场景:
int f(int a, int b, int c) { while(1) { if (a--==0||b>=c){ return 1; } }}成功使能ccmp指令,可以生成如下汇编代码:
图1 汇编包含ccmp指令示意图
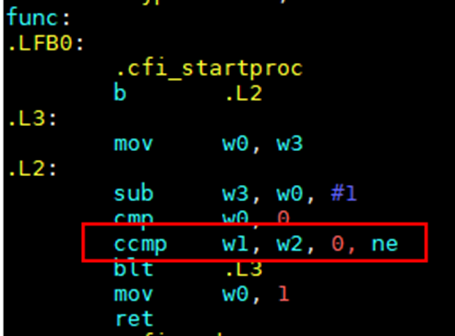
使用方法
增加编译选项 -fccmp2
须知
SPEC性能提升效果:SPECCPU2017 intrate 557.xz_r子项性能提升约1%
1.6.6 选项 -farray-widen-compare
数组宽比较优化:支持使用宽数据类型对原数组指针(指向的数组元素为窄类型)解引用,达到一次比较多个元素的效果,从而提高程序性能。
针对如下代码场景:
#define my_min(x, y) ((x) < (y) ? (x) : (y))
uint32_t func (uint32_t n0, uint32_t n1, const uint32_t limit, const uint8_t * a, const uint8_t * b)
{
uint32_t n = my_min(n0, n1);
while (++n != limit)
if (a[n] != b[n])
break;
return n;}添加选项后,可以优化为如下代码:
#define my_min(x, y) ((x) < (y) ? (x) : (y))
uint32_t func (uint32_t n0, uint32_t n1, const uint32_t limit, const uint8_t * a, const uint8_t * b)
{
uint32_t n = my_min(n0, n1);
for (++n; n + sizeof(uint64_t) <= limit; n += sizeof(uint64_t))
{
uint64_t k1 = *((uint64_t*)(a+n));
uint64_t k2 = *((uint64_t*)(b+n));
if(k1 != k2)
{
int lz = __builtin_ctzll(k1 ^ k2);
n += lz/8;
return n;
}
}
for (;n != limit; ++n)
{
if (a[n] != b[n])
break;
}
return n;
}使用方法
增加编译选项-O3 -farray-widen-compare
2 AI For Compiler
2.1 采样反馈优化能力增强
2.1.1 特性描述
AI4Compiler通过相关算法及构建框架,可以在进一步增强采样反馈优化能力特性,更准确的预估编译优化过程中的关键数值,辅助编译器做出更合理的优化决策,提升编译优化效果。AI4Compiler通过代码表征学习等AI4Compiler算法,训练BOLT采样的基本块精度修正模型,构建框架集成至GCC for OpenEuler,实现性能提升。
BOLT通过改进二进制文件中的代码和数据布局来减少CPU的缓存未命中率和分支预测错误,从而在编译器在应用了链接时优化(LTO)以及反馈驱动优化(FDO)后提供进一步的优化。BOLT在利用动态profiling数据提高程序的运行性能时有两种不同的方式:即插桩和采样。插桩方式性能开销大但精度较高,采样方式性能开销微乎其微但精度不及插桩。而BOLT采样的基本块精度修正模型则力图通过挖掘一个BB块的内含指令/变量、所处函数/文件等多粒度代码信息来对其Count值进行预测,从而提高CFG的准确性,使采样BOLT达到接近插装BOLT的优化效果。
2.1.2 下载安装步骤
使用root权限,安装rpmbuild、rpmdevtools
bash## 安装rpmbuild yum install rpm-build ## 安装rpmdevtools yum install rpmdevtools从目标仓库拉取代码
bashgit clone https://atomgit.com/src-openeuler/AI4C.git生成rpmbuild文件夹
bashrpmbuild-setuptree将拉取代码中的AI4C-v0.2.0-alpha.tar.gz和相关patch文件放入rpmbuild中的SOURCES文件夹中,将AI4C.spec放入rpmbuild中的SPECS目录下。安装AI4C
bashrpm -ivh \<成功构建的rpm>(若系统因存有旧版本安装包而导致的文件冲突,可以在rpm -ivh <成功构建的rpm>命令中添加一行--force选项,强制安装新版本;或者通过rpm -Uvh <成功构建的rpm>命令更新安装包)。
待安装完成后,可在/usr/lib64下找到相关动态库,在/usr/lib64/AI4C目录下找到相关模型。
2.1.3 使用步骤
AI4C支持用户调用API使用自定义模型进行推理,也支持借助编译选项使用预设模型使用采样反馈优化能力增强特性和优化选项调优特性。
使用自定义模型推理:
开发者首先需要构建自己的模型并借助onnxruntime保存成一个ONNX模型。
用户需要在目标优化遍的适配层里调用AI4C提供的API,进行模型的推理,如下表所示。下表的接口存在动态库libONNXRunner.so中,用于模型的推理配置阶段、推理运行阶段和模型推理结束后的资源清理阶段。
API名 说明 extern ONNXRunner* createONNXRunner(const char* model_path)参数为模型存放的路径,并创建session对本次推理进行初始化和配置 extern void deleteONNXRunner(ONNXRunner* instance)删除ONNXRunner对象 extern float runONNXModel(ONNXRunner* instance, std::vector<std::string> input_string, std::vector<int64_t>input_int64, std::vector<float> input_float)参数为模型的输入,将输入传入模型进行推理得到相应结果
2.1.4 常用应用提升效果
本次测试使用MySQL应用程序作为测试程序。MySQL是一种流行的开源关系型数据库管理系统(RDBMS),广泛应用于各种应用中。通过AI4Compiler算法及框架,可以在BOLT优化阶段更准确的预估编译优化过程中的关键数值,辅助编译器做出更合理的优化决策,提升编译优化效果,从而实现MySQL性能提升。根据对MySQL的运行tpmC吞吐量测试结果,AI4Compiler框架结合调优选项可以帮助MySQL性能提升5%。
3 插件框架
3.1 特性描述
编译器插件框架致力于让开发者减少开发成本,即基于编译能力的相关工具开发者只需要做一次开发,便可在多个不同编译器框架落地。同时编译器插件框架作为开发平台,也提供对公共能力的支持与维护。编译器插件框架采用代理模式,由服务端和客户端两个关键组件构成。插件服务端专注于承载插件逻辑,允许开发者基于相对中立的MLIR和我们提供的一系列插件API进行开发,使开发者能够将关注点聚焦于工具的设计逻辑上。服务端与不同编译器的客户端对接,通过跨进程通信传递IR数据与操作,将插件逻辑转换映射,并最终在客户端编译器上执行,从而实现了一份代码可以在多个编译器上落地的目的。
插件使用者只需要下载所需插件的库文件和校验文件,通过框架的配置文件即可与编译器客户端联合使能。插件客户端将作为GCC/LLVM Plugin进行加载,具有不需要修改GCC编译器源代码即可实现新功能的优势,使得用户能够更加灵活和便捷地使用插件,同时享受框架支持与维护的各种公共能力。
3.2 下载安装步骤
安装依赖软件
bash## 安装GCC客户端依赖软件: yum install -y gityum install -y makeyum install -y cmakeyum install -y grpcyum install -y grpc-develyum install -y grpc-pluginsyum install -y protobuf-develyum install -y jsoncppyum install -y jsoncpp-develyum install -y gcc-plugin-develyum install -y llvm-mliryum install -y llvm-mlir-develyum install -y llvm-devel ## 安装插件框架服务端依赖软件 yum install -y gityum install -y makeyum install -y cmakeyum install -y grpcyum install -y grpc-develyum install -y grpc-pluginsyum install -y protobuf-develyum install -y jsoncppyum install -y jsoncpp-develyum install -y llvm-mliryum install -y llvm-mlir-develyum install -y llvm-devel安装/构建插件框架,可以采用以下两种方式进行
编译构建
bash## 构建插件框架GCC客户端 git clone https://atomgit.com/openeuler/pin-gcc-client.gitcd pin-gcc-clientmkdir buildcd buildcmake ../ -DMLIR_DIR=${MLIR_PATH} -DLLVM_DIR=${LLVM_PATH}make ## 构建插件框架服务端 git clone https://atomgit.com/openeuler/pin-server.gitcd pin-servermkdir buildcd buildcmake ../ -DMLIR_DIR=${MLIR_PATH} -DLLVM_DIR=${LLVM_PATH}makeyum安装
bash## yum安装插件框架GCC客户端 yum install -y pin-gcc-client ## yum安装插件框架服务端 yum install -y pin-server
4 多版本GCC
4.1 特性描述
为确保操作系统的稳健性,基础软件的选型策略通常倾向于采用经过时间验证、相对稳定的版本,而非最新发布版本。这一策略旨在避免版本更迭带来的潜在不稳定因素,确保在整个长期支持(LTS)周期内,系统版本保持相对稳定。因此,当前 openEuler 在 24.03 LTS 版本整个生命周期都是选择使用 GCC 12.3.1 作为基线进行开发。
这样的选择会带来如下问题。首先,许多的硬件特性需要基础 GCC 工具链的支持,选择非最新版本的 GCC 会导致新特性无法及时在新发布的操作系统上使能。另外,某些用户倾向使用最新版本的编译器使能最新特性,这些特性相较于低版本编译器会带来部分性能提升。
因此,为了使能多样算例新特性,满足不同用户对不同硬件特性支持的需求,在 openEuler 24.09 版本推出 openEuler GCC Toolset 工具链,这是一个专为 openEuler 系统设计的 GCC 多版本编译工具链,该工具链提供一个高于系统主 GCC 版本的副版本 GCC 编译工具链,为用户提供了更加灵活且高效的编译环境选择。通过使用 openEuler GCC Toolset 多版本编译工具链,用户可以轻松地在不同版本的 GCC 之间进行切换,以便充分利用新硬件特性,同时享受到 GCC 最新优化所带来的性能提升。
4.2 使用约束
在默认 GCC 版本为 GCC 12.3.1 的 openEuler24.09 版本中,提供 gcc-toolset-14 的副版本编译工具链,形成主编译器版本为 GCC 12,副版本编译器为 GCC 14 的搭配;
- 操作系统:openEuler 24.09
- 硬件架构:Aarch64 / X86_64
4.3 下载安装步骤
4.3.1 安装scl
yum install scl-utils scl-utils-build4.3.2 安装多版本工具链
副版本编译工具链 gcc-toolset-14 安装路径为 /opt/openEuler/gcc-toolset-14/:
yum install -y gcc-toolset-14-gcc*
yum install -y gcc-toolset-14-binutils*4.4 使用方式
本方案引入 SCL(Software Collections)工具进行不同版本编译工具链的管理。
4.4.1 注册 gcc-toolset-14
## 注册gcc-toolset-14
scl register /opt/openEuler/gcc-toolset-14/
##取消注册 gcc-toolset-14
scl deregister gcc-toolset-14
使用scl list-collections显示 gcc-toolset-14 表明已经在 scl 中注册成功;4.4.2 切换 gcc-toolset-14
启动一个新的bash shell会话,其中使用 gcc-toolset-14 内的工具版本,而不是系统默认版本。在新的bash shell会话中,无需显式使用scl命令。
scl enable gcc-toolset-14 bash如果需要退出 gcc-toolset-14 的编译环境,输入exit退出bash shell会话,此时gcc的版本切换成系统默认版本。
SCL工具的本质就是自动设置不同工具版本的环境变量,具体可以参考 /opt/openEuler/gcc-toolset-14/enable 文档,gcc-toolset-14 的环境变量均在该文件中设置。若用户系统没有 SCL 工具,则可以使用以下方式进行工具链版本切换:
## 方案一:无 SCL 工具,使用脚本切换编译工具链
source /opt/openEuler/gcc-toolset-14/enable
## 方案二:有 SCL 工具,使用 SCL 工具切换编译工具链并激活运行环境
scl enable gcc-toolset-14 bash4.5 使用场景
主版本场景:正常编译使用系统默认的 gcc-12.3.1;
副版本场景:需要使用 GCC-14 高版本特性构建相关应用,使用 SCL 工具将 bash 环境切换为 gcc-toolset-14 编译工具链的编译环境。
遵循 木兰宽松许可证第2版(MulanPSL2)
