
gala-spider使用手册
本章主要介绍如何部署和使用gala-spider和gala-inference。
gala-spider
gala-spider 提供 OS 级别的拓扑图绘制功能,它将定期获取 gala-gopher (一个 OS 层面的数据采集软件)在某个时间点采集的所有观测对象的数据,并计算它们之间的拓扑关系,最终将生成的拓扑图保存到图数据库 arangodb 中。
安装
挂载 yum 源:
[oe-2209] # openEuler 22.09 官方发布源
name=oe2209
baseurl=http://119.3.219.20:82/openEuler:/22.09/standard_x86_64
enabled=1
gpgcheck=0
priority=1
[oe-2209:Epol] # openEuler 22.09:Epol 官方发布源
name=oe2209_epol
baseurl=http://119.3.219.20:82/openEuler:/22.09:/Epol/standard_x86_64/
enabled=1
gpgcheck=0
priority=1
安装 gala-spider:
# yum install gala-spider
配置
配置文件说明
gala-spider 配置文件为 /etc/gala-spider/gala-spider.yaml ,该文件配置项说明如下。
- global:全局配置信息。
- data_source:指定观测指标采集的数据库,当前只支持 prometheus。
- data_agent:指定观测指标采集代理,当前只支持 gala_gopher。
- spider:spider配置信息。
- log_conf:日志配置信息。
- log_path:日志文件路径。
- log_level:日志打印级别,值包括 DEBUG/INFO/WARNING/ERROR/CRITICAL 。
- max_size:日志文件大小,单位为兆字节(MB)。
- backup_count:日志备份文件数量。
- log_conf:日志配置信息。
- storage:拓扑图存储服务的配置信息。
- period:存储周期,单位为秒,表示每隔多少秒存储一次拓扑图。
- database:存储的图数据库,当前只支持 arangodb。
- db_conf:图数据库的配置信息。
- url:图数据库的服务器地址。
- db_name:拓扑图存储的数据库名称。
- kafka:kafka配置信息。
- server:kafka服务器地址。
- metadata_topic:观测对象元数据消息的topic名称。
- metadata_group_id:观测对象元数据消息的消费者组ID。
- prometheus:prometheus数据库配置信息。
- base_url:prometheus服务器地址。
- instant_api:单个时间点采集API。
- range_api:区间采集API。
- step:采集时间步长,用于区间采集API。
配置文件示例
global:
data_source: "prometheus"
data_agent: "gala_gopher"
prometheus:
base_url: "http://localhost:9090/"
instant_api: "/api/v1/query"
range_api: "/api/v1/query_range"
step: 1
spider:
log_conf:
log_path: "/var/log/gala-spider/spider.log"
# log level: DEBUG/INFO/WARNING/ERROR/CRITICAL
log_level: INFO
# unit: MB
max_size: 10
backup_count: 10
storage:
# unit: second
period: 60
database: arangodb
db_conf:
url: "http://localhost:8529"
db_name: "spider"
kafka:
server: "localhost:9092"
metadata_topic: "gala_gopher_metadata"
metadata_group_id: "metadata-spider"
启动
通过命令启动。
# spider-storage通过 systemd 服务启动。
# systemctl start gala-spider
使用方法
外部依赖软件部署
gala-spider 运行时需要依赖多个外部软件进行交互。因此,在启动 gala-spider 之前,用户需要将gala-spider依赖的软件部署完成。下图为 gala-spider 项目的软件依赖图。
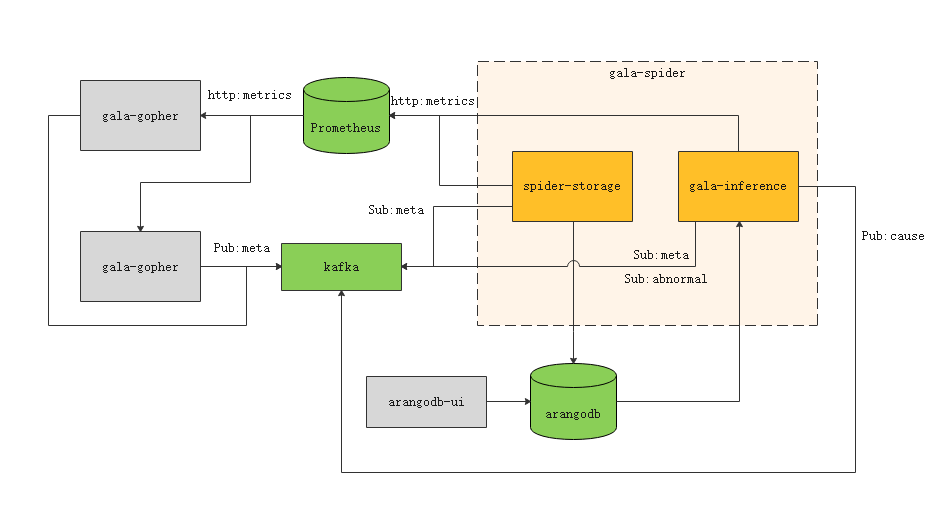
其中,右侧虚线框内为 gala-spider 项目的 2 个功能组件,绿色部分为 gala-spider 项目直接依赖的外部组件,灰色部分为 gala-spider 项目间接依赖的外部组件。
- spider-storage:gala-spider 核心组件,提供拓扑图存储功能。
- 从 kafka 中获取观测对象的元数据信息。
- 从 Prometheus 中获取所有的观测实例信息。
- 将生成的拓扑图存储到图数据库 arangodb 中。
- gala-inference:gala-spider 核心组件,提供根因定位功能。它通过订阅 kafka 的异常 KPI 事件触发异常 KPI 的根因定位流程,并基于 arangodb 获取的拓扑图来构建故障传播图,最终将根因定位的结果输出到 kafka 中。
- prometheus:时序数据库,gala-gopher 组件采集的观测指标数据会上报到 prometheus,再由 gala-spider 做进一步处理。
- kafka:消息中间件,用于存储 gala-gopher 上报的观测对象元数据信息,异常检测组件上报的异常事件,以及 cause-inference 组件上报的根因定位结果。
- arangodb:图数据库,用于存储 spider-storage 生成的拓扑图。
- gala-gopher:数据采集组件,请提前部署gala-gopher。
- arangodb-ui:arangodb 提供的 UI 界面,可用于查询拓扑图。
gala-spider 项目中的 2 个功能组件会作为独立的软件包分别发布。
spider-storage 组件对应本节中的 gala-spider 软件包。
gala-inference 组件对应 gala-inference 软件包。
gala-gopher软件的部署参见gala-gopher使用手册,此处只介绍 arangodb 的部署。
当前使用的 arangodb 版本是 3.8.7 ,该版本对运行环境有如下要求:
- 只支持 x86 系统
- gcc10 以上
arangodb 官方部署文档参见:arangodb部署 。
arangodb 基于 rpm 的部署流程如下:
配置 yum 源。
[oe-2209] # openEuler 22.09 官方发布源 name=oe2209 baseurl=http://119.3.219.20:82/openEuler:/22.09/standard_x86_64 enabled=1 gpgcheck=0 priority=1 [oe-2209:Epol] # openEuler 22.09:Epol 官方发布源 name=oe2209_epol baseurl=http://119.3.219.20:82/openEuler:/22.09:/Epol/standard_x86_64/ enabled=1 gpgcheck=0 priority=1安装 arangodb3。
# yum install arangodb3配置修改。
arangodb3 服务器的配置文件路径为
/etc/arangodb3/arangod.conf,需要修改如下的配置信息:- endpoint:配置 arangodb3 的服务器地址
- authentication:访问 arangodb3 服务器是否需要进行身份认证,当前 gala-spider 还不支持身份认证,故此处将authentication设置为 false。
示例配置如下:
[server] endpoint = tcp://0.0.0.0:8529 authentication = false启动 arangodb3。
# systemctl start arangodb3
gala-spider配置项修改
依赖软件启动后,需要修改 gala-spider 配置文件的部分配置项内容。示例如下:
配置 kafka 服务器地址:
kafka:
server: "localhost:9092"
配置 prometheus 服务器地址:
prometheus:
base_url: "http://localhost:9090/"
配置 arangodb 服务器地址:
storage:
db_conf:
url: "http://localhost:8529"
启动服务
运行 systemctl start gala-spider 。查看启动状态可执行 systemctl status gala-spider ,输出如下信息说明启动成功。
[root@openEuler ~]# systemctl status gala-spider
● gala-spider.service - a-ops gala spider service
Loaded: loaded (/usr/lib/systemd/system/gala-spider.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2022-08-30 17:28:38 CST; 1 day 22h ago
Main PID: 2263793 (spider-storage)
Tasks: 3 (limit: 98900)
Memory: 44.2M
CGroup: /system.slice/gala-spider.service
└─2263793 /usr/bin/python3 /usr/bin/spider-storage
输出示例
用户可以通过 arangodb 提供的 UI 界面来查询 gala-spider 输出的拓扑图。使用流程如下:
在浏览器输入 arangodb 服务器地址,如:http://localhost:8529 ,进入 arangodb 的 UI 界面。
界面右上角切换至
spider数据库。在
Collections面板可以看到在不同时间段存储的观测对象实例的集合、拓扑关系的集合,如下图所示: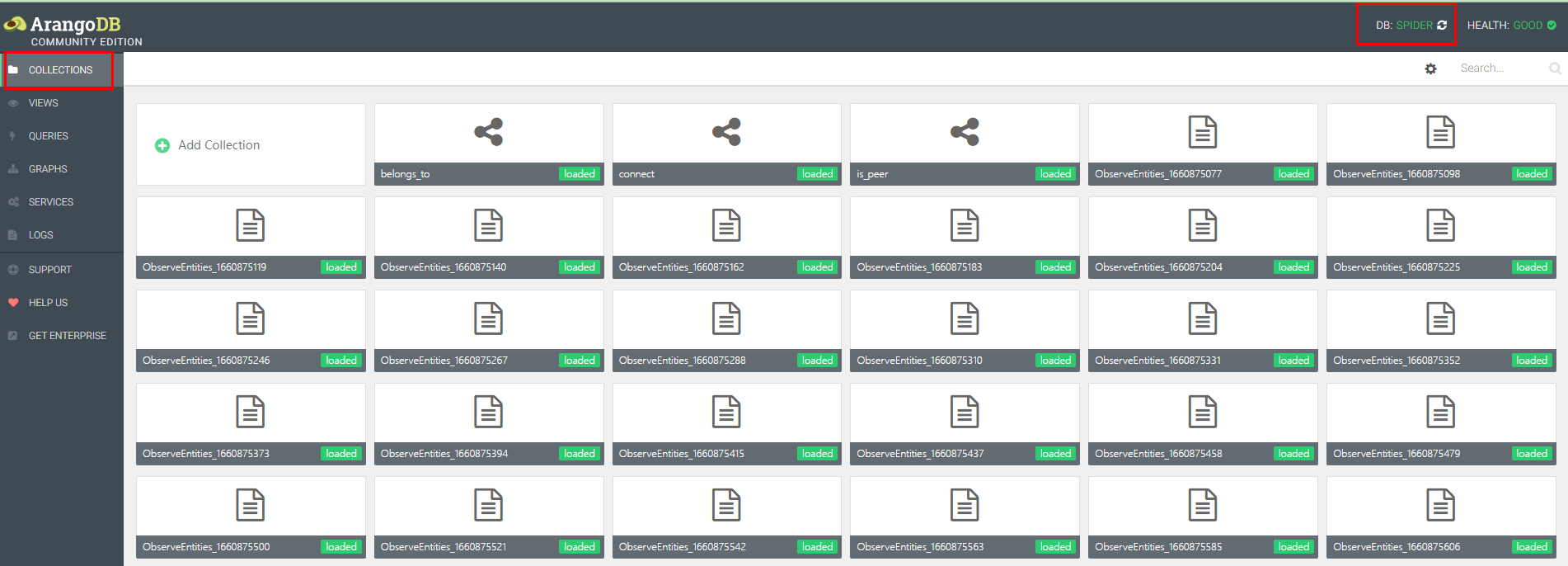
可进一步根据 arangodb 提供的 AQL 查询语句查询存储的拓扑关系图,详细教程参见官方文档: aql文档。
gala-inference
gala-inference 提供异常 KPI 根因定位能力,它将基于异常检测的结果和拓扑图作为输入,根因定位的结果作为输出,输出到 kafka 中。gala-inference 组件在 gala-spider 项目下进行归档。
安装
挂载 yum 源:
[oe-2209] # openEuler 22.09 官方发布源
name=oe2209
baseurl=http://119.3.219.20:82/openEuler:/22.09/standard_x86_64
enabled=1
gpgcheck=0
priority=1
[oe-2209:Epol] # openEuler 22.09:Epol 官方发布源
name=oe2209_epol
baseurl=http://119.3.219.20:82/openEuler:/22.09:/Epol/standard_x86_64/
enabled=1
gpgcheck=0
priority=1
安装 gala-inference:
# yum install gala-inference
配置
配置文件说明
gala-inference 配置文件 /etc/gala-inference/gala-inference.yaml 配置项说明如下。
- inference:根因定位算法的配置信息。
- tolerated_bias:异常时间点的拓扑图查询所容忍的时间偏移,单位为秒。
- topo_depth:拓扑图查询的最大深度。
- root_topk:根因定位结果输出前 K 个根因指标。
- infer_policy:根因推导策略,包括 dfs 和 rw 。
- sample_duration:指标的历史数据的采样周期,单位为秒。
- evt_valid_duration:根因定位时,有效的系统异常指标事件周期,单位为秒。
- evt_aging_duration:根因定位时,系统异常指标事件的老化周期,单位为秒。
- kafka:kafka配置信息。
- server:kafka服务器地址。
- metadata_topic:观测对象元数据消息的配置信息。
- topic_id:观测对象元数据消息的topic名称。
- group_id:观测对象元数据消息的消费者组ID。
- abnormal_kpi_topic:异常 KPI 事件消息的配置信息。
- topic_id:异常 KPI 事件消息的topic名称。
- group_id:异常 KPI 事件消息的消费者组ID。
- abnormal_metric_topic:系统异常指标事件消息的配置信息。
- topic_id:系统异常指标事件消息的topic名称。
- group_id:系统异常指标事件消息的消费者组ID。
- consumer_to:消费系统异常指标事件消息的超时时间,单位为秒。
- inference_topic:根因定位结果输出事件消息的配置信息。
- topic_id:根因定位结果输出事件消息的topic名称。
- arangodb:arangodb图数据库的配置信息,用于查询根因定位所需要的拓扑子图。
- url:图数据库的服务器地址。
- db_name:拓扑图存储的数据库名称。
- log_conf:日志配置信息。
- log_path:日志文件路径。
- log_level:日志打印级别,值包括 DEBUG/INFO/WARNING/ERROR/CRITICAL。
- max_size:日志文件大小,单位为兆字节(MB)。
- backup_count:日志备份文件数量。
- prometheus:prometheus数据库配置信息,用于获取指标的历史时序数据。
- base_url:prometheus服务器地址。
- range_api:区间采集API。
- step:采集时间步长,用于区间采集API。
配置文件示例
inference:
# 异常时间点的拓扑图查询所容忍的时间偏移,单位:秒
tolerated_bias: 120
topo_depth: 10
root_topk: 3
infer_policy: "dfs"
# 单位: 秒
sample_duration: 600
# 根因定位时,有效的异常指标事件周期,单位:秒
evt_valid_duration: 120
# 异常指标事件的老化周期,单位:秒
evt_aging_duration: 600
kafka:
server: "localhost:9092"
metadata_topic:
topic_id: "gala_gopher_metadata"
group_id: "metadata-inference"
abnormal_kpi_topic:
topic_id: "gala_anteater_hybrid_model"
group_id: "abn-kpi-inference"
abnormal_metric_topic:
topic_id: "gala_anteater_metric"
group_id: "abn-metric-inference"
consumer_to: 1
inference_topic:
topic_id: "gala_cause_inference"
arangodb:
url: "http://localhost:8529"
db_name: "spider"
log:
log_path: "/var/log/gala-inference/inference.log"
# log level: DEBUG/INFO/WARNING/ERROR/CRITICAL
log_level: INFO
# unit: MB
max_size: 10
backup_count: 10
prometheus:
base_url: "http://localhost:9090/"
range_api: "/api/v1/query_range"
step: 5
启动
通过命令启动。
# gala-inference通过 systemd 服务启动。
# systemctl start gala-inference
使用方法
依赖软件部署
gala-inference 的运行依赖和 gala-spider一样,请参见外部依赖软件部署。此外,gala-inference 还间接依赖 gala-spider 和 gala-anteater 软件的运行,请提前部署gala-spider和gala-anteater软件。
配置项修改
修改 gala-inference 的配置文件中部分配置项。示例如下:
配置 kafka 服务器地址:
kafka:
server: "localhost:9092"
配置 prometheus 服务器地址:
prometheus:
base_url: "http://localhost:9090/"
配置 arangodb 服务器地址:
arangodb:
url: "http://localhost:8529"
启动服务
直接运行 systemctl start gala-inference 即可。可通过执行 systemctl status gala-inference 查看启动状态,如下打印表示启动成功。
[root@openEuler ~]# systemctl status gala-inference
● gala-inference.service - a-ops gala inference service
Loaded: loaded (/usr/lib/systemd/system/gala-inference.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2022-08-30 17:55:33 CST; 1 day 22h ago
Main PID: 2445875 (gala-inference)
Tasks: 10 (limit: 98900)
Memory: 48.7M
CGroup: /system.slice/gala-inference.service
└─2445875 /usr/bin/python3 /usr/bin/gala-inference
输出示例
当异常检测模块 gala-anteater 检测到 KPI 异常后,会将对应的异常 KPI 事件输出到 kafka 中,gala-inference 会一直监测该异常 KPI 事件的消息,如果收到异常 KPI 事件的消息,就会触发根因定位。根因定位会将定位结果输出到 kafka 中,用户可以在 kafka 服务器中查看根因定位的输出结果,基本步骤如下:
若通过源码安装 kafka ,需要进入 kafka 的安装目录下。
cd /root/kafka_2.13-2.8.0执行消费 topic 的命令获取根因定位的输出结果。
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic gala_cause_inference输出示例如下:
{ "Timestamp": 1661853360000, "event_id": "1661853360000_1fd37742xxxx_sli_12154_19", "Atrributes": { "event_id": "1661853360000_1fd37742xxxx_sli_12154_19" }, "Resource": { "abnormal_kpi": { "metric_id": "gala_gopher_sli_rtt_nsec", "entity_id": "1fd37742xxxx_sli_12154_19", "timestamp": 1661853360000, "metric_labels": { "machine_id": "1fd37742xxxx", "tgid": "12154", "conn_fd": "19" } }, "cause_metrics": [ { "metric_id": "gala_gopher_proc_write_bytes", "entity_id": "1fd37742xxxx_proc_12154", "metric_labels": { "__name__": "gala_gopher_proc_write_bytes", "cmdline": "/opt/redis/redis-server x.x.x.172:3742", "comm": "redis-server", "container_id": "5a10635e2c43", "hostname": "openEuler", "instance": "x.x.x.172:8888", "job": "prometheus", "machine_id": "1fd37742xxxx", "pgid": "12154", "ppid": "12126", "tgid": "12154" }, "timestamp": 1661853360000, "path": [ { "metric_id": "gala_gopher_proc_write_bytes", "entity_id": "1fd37742xxxx_proc_12154", "metric_labels": { "__name__": "gala_gopher_proc_write_bytes", "cmdline": "/opt/redis/redis-server x.x.x.172:3742", "comm": "redis-server", "container_id": "5a10635e2c43", "hostname": "openEuler", "instance": "x.x.x.172:8888", "job": "prometheus", "machine_id": "1fd37742xxxx", "pgid": "12154", "ppid": "12126", "tgid": "12154" }, "timestamp": 1661853360000 }, { "metric_id": "gala_gopher_sli_rtt_nsec", "entity_id": "1fd37742xxxx_sli_12154_19", "metric_labels": { "machine_id": "1fd37742xxxx", "tgid": "12154", "conn_fd": "19" }, "timestamp": 1661853360000 } ] } ] }, "SeverityText": "WARN", "SeverityNumber": 13, "Body": "A cause inferring event for an abnormal event" }





