
硬件调优
配置BIOS
目的
针对不同的服务器硬件设备,通过设置BIOS中的一些高级配置选项,可以有效提升服务器性能。
方法
以下方法针对鲲鹏服务器进行调优,X86,例如Intel服务器,可选择保持默认BIOS配置。
关闭SMMU(鲲鹏服务器特有)。
重启服务器过程中,单击Delete键进入BIOS,选择“Advanced > MISC Config”,单击Enter键进入。
将“Support Smmu”设置为“Disable”。
注:此优化项只在非虚拟化场景使用,在虚拟化场景,则开启SMMU。
关闭预取
在BIOS中,选择“Advanced>MISC Config”,单击Enter键进入。
将“CPU Prefetching Configuration”设置为“Disabled”,单击F10键保存退出。
创建RAID0
目的
磁盘创建RAID可以提高磁盘的整体存取性能,环境上若使用的是LSI 3108/3408/3508系列RAID卡,推荐创建单盘RAID 0/RAID 5,充分利用RAID卡的Cache(LSI 3508卡为2GB),提高读写速率。
方法
使用storcli64_arm文件检查RAID组创建情况。
./storcli64_arm /c0 show注:storcli64_arm文件放在任意目录下执行皆可。文件下载路径:https://docs.broadcom.com/docs/007.1507.0000.0000_Unified_StorCLI.zip
创建RAID 0,命令表示为第2块1.2T硬盘创建RAID 0,其中,c0表示RAID卡所在ID、r0表示组RAID 0。依次类推,对除了系统盘之外的所有盘做此操作。
./storcli64_arm /c0 add vd r0 drives=65:1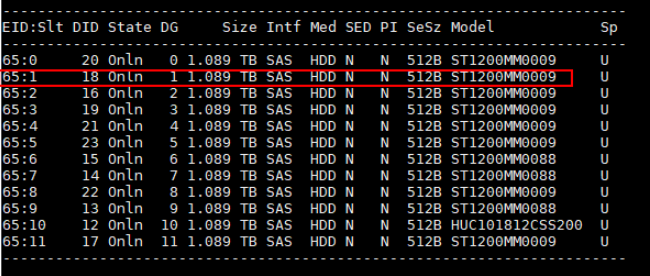
开启RAID卡Cache
目的
使用RAID卡的RAWBC(无超级电容)/RWBC(有超级电容)性能更佳。
使用storcli工具修改RAID组的Cache设置。Read Policy设置为Read ahead,使用RAID卡的Cache做预读。Write Policy设置为Write back,使用RAID卡的Cache做回写,而不是Write through透写。将IO policy设置为Cached IO,使用RAID卡的Cache缓存IO。
方法
- 配置RAID卡的cache,其中vx是卷组号(v0/v1/v2....),根据环境上的实际情况进行设置。
./storcli64_arm /c0/vx set rdcache=RA
./storcli64_arm /c0/vx set wrcache=WB/AWB
./storcli64_arm /c0/vx set iopolicy=Cached
- 检查配置是否生效。
./storcli64_arm /c0 show
调整rx_buff
目的
以1822网卡为例,默认的rx_buff配置为2KB,在聚合64KB报文的时候需要多片不连续的内存,使用率较低。该参数可以配置为2/4/8/16KB,修改后可以减少不连续的内存,提高内存使用率。
方法
查看rx_buff参数值,默认为2。
cat /sys/bus/pci/drivers/hinic/module/parameters/rx_buff在目录“/etc/modprobe.d/”中增加文件hinic.conf,修改rx_buff值为8。
options hinic rx_buff=8重新挂载hinic驱动,使得新参数生效。
rmmod hinic modprobe hinic查看rx_buff参数是否更新成功。
cat /sys/bus/pci/drivers/hinic/module/parameters/rx_buff
调整Ring Buffer
目的
以1822网卡为例,网卡队列深度Ring Buffer最大支持4096,默认配置为1024,可以增大buffer大小用于提高网卡Ring大小。
方法
查看Ring Buffer默认大小,假设当前网卡名为enp131s0。
ethtool -g enp131s0修改Ring Buffer值为4096。
ethtool -G enp131s0 rx 4096 tx 4096查看Ring Buffer值是否更新成功。
ethtool -g enp131s0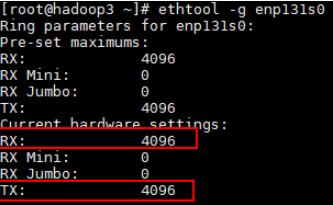
减少队列数。
ethtool -L enp131s0 combined 4 ethtool -l enp131s0
开启LRO
目的
以1822网卡为例,支持LRO(Large Receive Offload),可以打开该选项,并合理配置1822 LRO参数。
方法
查看LRO参数是否开启,默认为off,假设当前网卡名为enp131s0。
ethtool -k enp131s0打开LRO。
ethtool -K enp131s0 lro on查看LRO参数是否开启。
ethtool -k enp131s0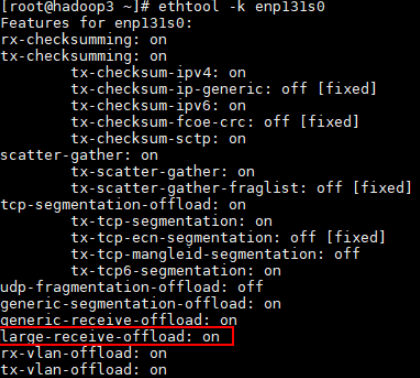
配置网卡中断绑核
目的
相比使用内核的irqbalance使网卡中断在所有核上进行调度,使用手动绑核将中断固定更能有效提高业务网络收发包的能力。
方法
关闭irqbalance。
若要对网卡进行绑核操作,则需要关闭irqbalance。
执行如下命令:
systemctl stop irqbalance.service #(停止irqbalance,重启失效)
systemctl disable irqbalance.service #(关闭irqbalance,永久生效)
systemctl status irqbalance.service #(查看irqbalance服务状态是否已关闭)
查看网卡pci设备号,假设当前网卡名为enp131s0。
ethtool -i enp131s0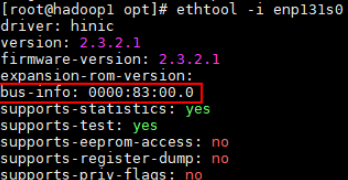
查看pcie网卡所属NUMA node。
lspci -vvvs <bus-info>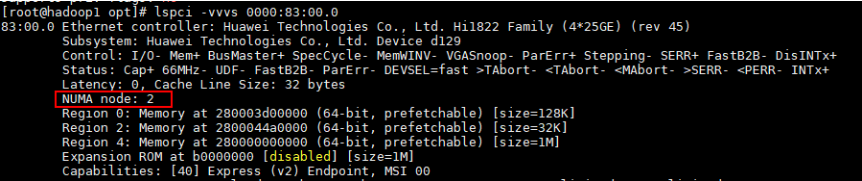
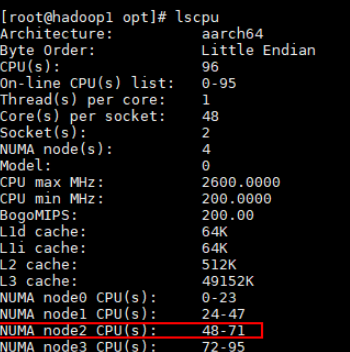
查看NUMA node对应的core的区间,例如此处在鲲鹏920 5250上就可以绑到48~63。
进行中断绑核,1822网卡共有16个队列,将这些中断逐个绑至所在NumaNode的16个Core上(例如此处是绑到NUMA node1对应48-63上)。
bash smartIrq.sh脚本内容如下:
#!/bin/bash irq_list=(`cat /proc/interrupts | grep enp131s0 | awk -F: '{print $1}'`) cpunum=48 # 修改为所在node的第一个Core for irq in ${irq_list[@]} do echo $cpunum > /proc/irq/$irq/smp_affinity_list echo `cat /proc/irq/$irq/smp_affinity_list` (( cpunum+=1 )) done利用脚本查看是否绑核成功。
sh irqCheck.sh enp131s0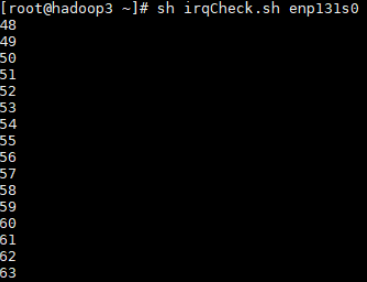
脚本内容如下:
#!/bin/bash # 网卡名 intf=$1 log=irqSet-`date "+%Y%m%d-%H%M%S"`.log # 可用的CPU数 cpuNum=$(cat /proc/cpuinfo |grep processor -c) # RX TX中断列表 irqListRx=$(cat /proc/interrupts | grep ${intf} | awk -F':' '{print $1}') irqListTx=$(cat /proc/interrupts | grep ${intf} | awk -F':' '{print $1}') # 绑定接收中断rx irq for irqRX in ${irqListRx[@]} do cat /proc/irq/${irqRX}/smp_affinity_list done # 绑定发送中断tx irq for irqTX in ${irqListTx[@]} do cat /proc/irq/${irqTX}/smp_affinity_list done
操作系统调优
关闭内存透明大页
目的
关闭内存透明大页,防止内存泄漏,减少卡顿。
方法
关闭内存透明大页。
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
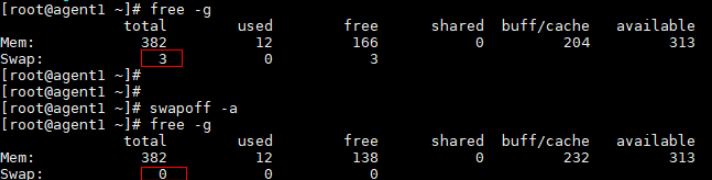
关闭swap分区
目的
Linux的虚拟内存会根据系统负载自动调整,内存页(page)swap到磁盘swap分区会影响测试性能。
方法
swapoff -a
修改前后对比如下。
spark组件调优
IO配置项调优
IO队列调整
- 目的
使用单队列(软队列)模式,单队列模式在spark测试时会有更佳的性能。
- 方法
在/etc/grub2-efi.cfg的内核启动命令行中添加
scsi_mod.use_blk_mq=0,重启生效。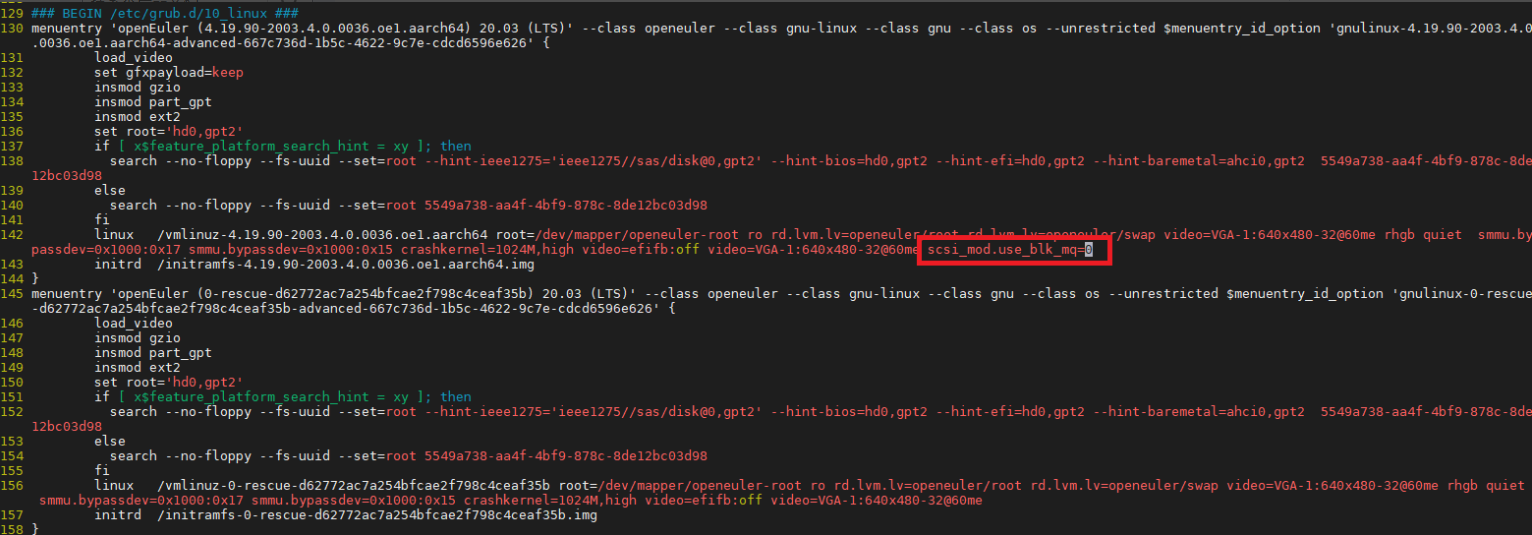
内核IO参数配置
#! /bin/bash echo 3000 > /proc/sys/vm/dirty_expire_centisecs echo 500 > /proc/sys/vm/dirty_writeback_centisecs echo 15000000 > /proc/sys/kernel/sched_wakeup_granularity_ns echo 10000000 > /proc/sys/kernel/sched_min_granularity_ns systemctl start tuned sysctl -w kernel.sched_autogroup_enabled=0 sysctl -w kernel.numa_balancing=0 echo 11264 > /proc/sys/vm/min_free_kbytes echo 60 > /proc/sys/vm/dirty_ratio echo 5 > /proc/sys/vm/dirty_background_ratio list="b c d e f g h i j k l m" #按需修改 for i in $list do echo 1024 > /sys/block/sd$i/queue/max_sectors_kb echo 32 > /sys/block/sd$i/device/queue_depth echo 256 > /sys/block/sd$i/queue/nr_requests echo mq-deadline > /sys/block/sd$i/queue/scheduler echo 2048 > /sys/block/sd$i/queue/read_ahead_kb echo 2 > /sys/block/sd$i/queue/rq_affinity echo 0 > /sys/block/sd$i/queue/nomerges done
JVM参数和版本适配
目的
最新版本的JDK对Spark性能进行了优化。
方法
可在spark-defaults.conf文件中添加以下配置来使用新的JDK,以使用新的JDK参数。
spark.executorEnv.JAVA_HOME /usr/local/jdk8u222-b10
spark.yarn.appMasterEnv.JAVA_HOME /usr/local/jdk8u222-b10
spark.executor.extraJavaOptions -XX:+UseNUMA -XX:BoxTypeCachedMax=100000
spark.yarn.am.extraJavaOptions -XX:+UseNUMA -XX:BoxTypeCachedMax=100000
注:X86架构,JVM参数-XX:BoxTypeCachedMax不适用。
spark应用参数调优
目的
在Spark基础配置值的基础上,按照理论公式得到一组较合理的Executor执行参数,使能后在鲲鹏上会带来明显的性能提升。
方法
如果用Spark-Test-Tool工具测试sql1~sql10场景,打开工具目录下的“script/spark-default.conf”文件,添加以下配置项:
yarn.executor.num 15 yarn.executor.cores 19 spark.executor.memory 44G spark.driver.memory 36G如果使用HiBench工具测试wordcount、terasort、bayesian、kmeans场景,打开工具目录下的“conf/spark.conf”文件,可以根据实际环境对运行核数、内存大小做调整。
yarn.executor.num 15 yarn.executor.cores 19 spark.executor.memory 44G spark.driver.memory 36G
专用场景优化项
SQL场景
sql1-IO密集型SQL
目的
sql1是IO密集型场景,可以通过优化IO参数带来最佳性能。
方法
对以下IO相关参数进行设置,其中sd$i指所有参与测试的磁盘名。
echo 128 > /sys/block/sd$i/queue/nr_requests echo 512 > /sys/block/sd$i/queue/read_ahead_kb对内存脏页参数进行设置。
/proc/sys/vm/vm.dirty_expire_centisecs 500 /proc/sys/vm/vm.dirty_writeback_centisecs 100并行度在Spark-Test-Tool/script/spark-default.conf里设置。
spark.sql.shuffle.partitions 350 spark.default.parallelism 580该场景其余参数都使用spark应用参数调优中的通用优化值。
sql2 & sql7 - CPU密集型SQL
目的
sql2和sql7是CPU密集型场景,可以通过优化spark执行参数带来最佳性能。
方法
Spark-Test-Tool在配置文件(script/spark-default.conf)中指定的运行核数、内存大小可以根据实际环境来做调整,从而达到最优性能。如对于鲲鹏920 5220处理器,sql2和sql7场景建议以下executor参数。
yarn.executor.num 42 yarn.executor.cores 6 spark.executor.memory 15G spark.driver.memory 36G并行度在Spark-Test-Tool/script/spark-default.conf里设置
针对sql2,设置如下:
spark.sql.shuffle.partitions 150 spark.default.parallelism 504针对sql7,设置如下:
spark.sql.shuffle.partitions 300 spark.default.parallelism 504
sql3-IO + CPU
目的
sql3是IO+CPU密集型场景,可以通过优化spark执行参数、调整IO参数来带来最佳性能。
方法
Spark-Test-Tool在配置文件(script/spark-default.conf)中指定的运行核数、内存大小可以根据实际环境来做调整,来达到最优性能。比如对于鲲鹏920 5220处理器,sql3场景建议以下executor参数。
yarn.executor.num 30 yarn.executor.cores 6 spark.executor.memory 24G spark.driver.memory 36G调整IO预取值,其中sd$i表示所有参与spark的磁盘名。
echo 4096 > /sys/block/sd$i/queue/read_ahead_kb并行度在Spark-Test-Tool/script/spark-default.conf里设置。
spark.sql.shuffle.partitions 150 spark.default.parallelism 360
sql4 - CPU密集
目的
sql4是CPU密集型场景,可以优化spark执行参数、调整IO参数来带来最佳性能。
方法
Spark-Test-Tool在配置文件中指定的运行核数、内存大小可以根据实际环境来做调整,来达到最优性能。比如对于鲲鹏920 5220处理器,sql4场景建议以下executor参数。
打开工具目录下的script/spark-default.conf文件,添加以下配置项:
yarn.executor.num 42 yarn.executor.cores 6 spark.executor.memory 15G spark.driver.memory 36G同时调整IO预取值,其中sd$i表示所有参与spark的磁盘名:
echo 4096 > /sys/block/sd$i/queue/read_ahead_kb并行度在Spark-Test-Tool/script/spark-default.conf里设置。
spark.sql.shuffle.partitions 150 spark.default.parallelism 504
sql5 & sql6 & sql8 & sql9 & sql10
并行度在Spark-Test-Tool/script/spark-default.conf里设置。
spark.sql.shuffle.partitions 300 spark.default.parallelism 504该场景其余参数都使用spark应用参数调优的通用优化值。
HiBench场景
Wordcount – IO + CPU密集型
目的
Wordcount是IO+CPU密集型场景,二者均衡,采用单队列的deadline调度算法反而不好,采用多队列的mq-deadline算法并调整相关io参数,能得到较好的性能结果。
方法
对以下配置进行修改,其中sd$i指所有参与测试的磁盘名称:
echo mq-deadline > /sys/block/sd$i/queue/scheduler echo 512 > /sys/block/sd$i/queue/nr_requests echo 8192 > /sys/block/sd$i/queue/read_ahead_kb echo 500 > /proc/sys/vm/dirty_expire_centisecs echo 100 > /proc/sys/vm/dirty_writeback_centisecs echo 5 > /proc/sys/vm/dirty_background_ratio该场景下采用3-5倍总核数作为数据分片的Partitions和 Parallelism进行数据分片,减小单Task文件大小,对性能有正面提升。可以使用以下分片设置:
spark.sql.shuffle.partitions 300 spark.default.parallelism 600HiBench在配置文件中指定的运行核数、内存大小可以根据实际环境来做调整,来达到最优性能。比如对于鲲鹏920 5220处理器,Wordcount场景建议以下executor参数:
yarn.executor.num 51 yarn.executor.cores 6 spark.executor.memory 13G spark.driver.memory 36G
Terasort – IO + CPU 密集型
目的
Terasort是IO和CPU密集型场景,可以对IO参数和spark执行参数进行调整。另外,Terasort对网络的带宽要求也较高,可以通过优化网络参数,提升系统性能。
方法
对以下配置进行修改,其中sd$i指所有参与测试的磁盘名称。
echo bfq > /sys/block/sd$i/queue/scheduler echo 512 > /sys/block/sd$i/queue/nr_requests echo 8192 > /sys/block/sd$i/queue/read_ahead_kb echo 4 > /sys/block/sd$i/queue/iosched/slice_idle echo 500 > /proc/sys/vm/dirty_expire_centisecs echo 100 > /proc/sys/vm/dirty_writeback_centisecs该场景下采用3-5倍总核数作为数据分片的Partitions和 Parallelism进行数据分片,减小单Task文件大小,对性能有正面提升。打开HiBench工具的“conf/spark.conf”文件,可以使用以下分片设置:
spark.sql.shuffle.partitions 1000 spark.default.parallelism 2000打开HiBench工具的“conf/spark.conf”文件,增加以下executor参数:
yarn.executor.num 27 yarn.executor.cores 7 spark.executor.memory 25G spark.driver.memory 36G优化网络参数。
ethtool -K enp131s0 gro on ethtool -K enp131s0 tso on ethtool -K enp131s0 gso on ethtool -G enp131s0 rx 4096 tx 4096 ethtool -G enp131s0 rx 4096 tx 4096 # TM 280网卡最大可支持MTU=9000 ifconfig enp131s0 mtu 9000 up
Bayesian – CPU密集型
目的
Bayesian是CPU密集型场景,可以对IO参数和spark执行参数进行调整。
方法
该场景可以使用以下分片设置:
spark.sql.shuffle.partitions 1000 spark.default.parallelism 2500打开HiBench工具的“conf/spark.conf”文件,增加以下executor参数:
yarn.executor.num 9 yarn.executor.cores 25 spark.executor.memory 73G spark.driver.memory 36G该场景使用以下内核参数:
echo mq-deadline > /sys/block/sd$i/queue/scheduler echo 0 > /sys/module/scsi_mod/parameters/use_blk_mq echo 50 > /proc/sys/vm/dirty_background_ratio echo 80 > /proc/sys/vm/dirty_ratio echo 500 > /proc/sys/vm/dirty_expire_centisecs echo 100 > /proc/sys/vm/dirty_writeback_centisecs
Kmeans – CPU密集型
目的
Kmeans是CPU密集型场景,可以对IO参数和spark执行参数进行调整。
方法
主要是调整spark executor参数适配到一个较优值,该场景可以使用以下分片设置:
spark.sql.shuffle.partitions 1000 spark.default.parallelism 2500调整IO预取值,其中sd$i表示所有参与spark的磁盘名:
echo 4096 > /sys/block/sd$i/queue/read_ahead_kb打开HiBench工具的“conf/spark.conf”文件,增加以下executor参数:
yarn.executor.num 42 yarn.executor.cores 6 spark.executor.memory 15G spark.driver.memory 36G spark.locality.wait 10s
Hive组件调优
IO配置项调优
主要涉及scheduler、read_ahead_kb、sector_size配置。
scheduler推荐使用mq-deadline,可以达到更高的IO效率,从而提高性能。
块设备的预读推荐设置为4M,读性能更佳,默认值一般为128KB。
块设备的sector_size应与物理盘的扇区大小进行匹配。可通过hw_sector_size、max_hw_sectors_kb、max_sectors_kb三者进行匹配,前两者是从硬件中读取出来的值,第三者是内核块设备的聚合最大块大小,推荐与硬件保持一致,即后两者参数保证一致。
对涉及的所有数据盘统一设置如下:
list="b c d e f g h i j k l m" #按需修改
for i in $list
do
echo mq-deadline > /sys/block/sd$i/queue/scheduler
echo 4096 > /sys/block/sd$i/queue/read_ahead_kb
echo 512 > sys/block/sd$i/queue/hw_sector_size
echo 1024 > /sys/block/sd$i/queue/max_hw_sectors_kb
echo 256 > /sys/block/sd$i/queue/max_sectors_kb
done
内存脏页参数调优
echo 500 > /proc/sys/vm/dirty_expire_centisecs
echo 100 > /proc/sys/vm/dirty_writeback_centisecs
Hive调优
组件参数配置
| 组件 | 参数名 | 推荐值 | 修改原因 |
|---|---|---|---|
| Yarn->NodeManager Yarn->ResourceManager | ResourceManager Java heap size | 1024 | 修改JVM内存大小,保证内存水平较高,减少GC的频率。 说明: 非固定值,需要根据GC的释放情况来调大或调小Xms及Xmx的值。 |
| Yarn->NodeManager Yarn->ResourceManager | NodeManager Java heap size | 1024 | |
| Yarn->NodeManager | yarn.nodemanager.resource.cpu-vcores | 与实际数据节点的总物理核数相等。 | 可分配给Container的CPU核数。 |
| Yarn->NodeManager | yarn.nodemanager.resource.memory-mb | 与实际数据节点物理内存总量相等。 | 可分配给Container的内存。 |
| Yarn->NodeManager | yarn.nodemanager.numa-awareness.enabled | true | NodeManager启动Container时的Numa感知,需手动添加。 |
| Yarn->NodeManager | yarn.nodemanager.numa-awareness.read-topology | true | NodeManager的Numa拓扑自动感知,需手动添加。 |
| MapReduce2 | mapreduce.map.memory.mb | 7168 | 一个Map Task可使用的内存上限。 |
| MapReduce2 | mapreduce.reduce.memory.mb | 14336 | 一个Reduce Task可使用的资源上限。 |
| MapReduce2 | mapreduce.job.reduce.slowstart.completedmaps | 0.35 | 当Map完成的比例达到该值后才会为Reduce申请资源。 |
| HDFS->NameNode | NameNode Java heap size | 3072 | 修改JVM内存大小,保证内存水平较高,减少GC的频率。 |
| HDFS->NameNode | NameNode new generation size | 384 | |
| HDFS->NameNode | NameNode maximum new generation size | 384 | |
| HDFS->NameNode | dfs.namenode.service.handler.count | 32 | NameNode RPC服务端监测DataNode和其他请求的线程数,可适量增加。 |
| HDFS->NameNode | dfs.namenode.handler.count | 1200 | NameNode RPC服务端监测客户端请求的线程数,可适量增加。 |
| HDFS->DataNode | dfs.datanode.handler.count | 512 | DataNode服务线程数,可适量增加。 |
| TEZ | tez.am.resource.memory.mb | 7168 | 等同于yarn.scheduler.minimum-allocation-mb,默认7168。 |
| TEZ | tez.runtime.io.sort.mb | SQL1: 32 SQL2: 256 SQL3: 256 SQL4: 128 SQL5: 64 | 根据不同的场景进行调整。 |
| TEZ | tez.am.container.reuse.enabled | true | Container重用开关。 |
| TEZ | tez.runtime.unordered.output.buffer.size-mb | 537 | 10%* hive.tez.container.size。 |
| TEZ | tez.am.resource.cpu.vcores | 10 | 使用的虚拟CPU数量,默认1,需要手动添加。 |
| TEZ | tez.container.max.java.heap.fraction | 0.85 | 基于Yarn提供的内存,分配给java进程的百分比,默认是0.8,需要手动添加。 |
numa特性开启
Yarn组件在3.1.0版本合入的新特性支持,支持Yarn组件在启动Container时使能NUMA感知功能,原理是读取系统物理节点上每个NUMA节点的CPU核、内存容量,使用Numactl命令指定启动container的CPU范围和membind范围,减少跨片访问。
- 安装numactl
yum install numactl.aarch64
- 开启NUMA感知
yarn.nodemanager.numa-awareness.enabled true
yarn.nodemanager.numa-awareness.read-topology true
在组件参数配置已列出。
Hbase组件调优
Hbase调优
组件参数配置
如下参数为本次测试所配置参数,x86计算平台和鲲鹏920计算平台参数仅有Yarn部分参数有差异(差异处表格中有体现),hbase和hdfs采用同一套参数进行测试。
| 组件 | 参数名 | 推荐值 | 修改原因 |
|---|---|---|---|
| Yarn->NodeManager Yarn->ResourceManager | ResourceManager Java heap size | 1024 | 修改JVM内存大小,保证内存水平较高,减少GC的频率。 |
| Yarn->NodeManager Yarn->ResourceManager | NodeManager Java heap size | 1024 | |
| Yarn->NodeManager | yarn.nodemanager.resource.cpu-vcores | 与实际数据节点的总物理核数相等。 | 可分配给Container的CPU核数。 |
| Yarn->NodeManager | yarn.nodemanager.resource.memory-mb | 与实际数据节点物理内存总量相等。 | 可分配给Container的内存。 |
| Yarn->NodeManager | yarn.nodemanager.numa-awareness.enabled | true | NodeManager启动Container时的Numa感知,需手动添加。 |
| Yarn->NodeManager | yarn.nodemanager.numa-awareness.read-topology | true | NodeManager的Numa拓扑自动感知,需手动添加。 |
| MapReduce2 | mapreduce.map.memory.mb | 7168 | 一个Map Task可使用的内存上限。 |
| MapReduce2 | mapreduce.reduce.memory.mb | 14336 | 一个Reduce Task可使用的资源上限。 |
| MapReduce2 | mapreduce.job.reduce.slowstart.completedmaps | 0.35 | 当Map完成的比例达到该值后才会为Reduce申请资源。 |
| HDFS->NameNode | NameNode Java heap size | 3072 | 修改JVM内存大小,保证内存水平较高,减少GC的频率。 |
| HDFS->NameNode | NameNode new generation size | 384 | |
| HDFS->NameNode | NameNode maximum new generation size | 384 | |
| HDFS->NameNode | dfs.namenode.service.handler.count | 128 | NameNode RPC服务端监测DataNode和其他请求的线程数,可适量增加。 |
| HDFS->NameNode | dfs.namenode.handler.count | 1200 | NameNode RPC服务端监测客户端请求的线程数,可适量增加。 |
| HDFS->DataNode | dfs.datanode.handler.count | 512 | DataNode服务线程数,可适量增加。 |
| HBase->RegionServer | HBase RegionServer Maximum Memory | 31744 | 修改JVM内存大小,保证内存水平较高,减少GC的频率。 |
| HBase->RegionServer | hbase.regionserver.handler.count | 150 | RegionServer上的RPC服务器实例数量。 |
| HBase->RegionServer | hbase.regionserver.metahandler.count | 150 | RegionServer中处理优先请求的程序实例的数量。 |
| HBase->RegionServer | hbase.regionserver.global.memstore.size | 0.4 | 最大JVM堆大小(Java -Xmx设置)分配给MemStore的比例。 |
| HBase->RegionServer | hfile.block.cache.size | 0.4 | 数据缓存所占的RegionServer GC -Xmx百分比。 |
| HBase->RegionServer | hbase.hregion.memstore.flush.size | 267386880 | Regionserver memstore大小,增大可以减小阻塞。 |
numa特性开启
Yarn组件在3.1.0版本合入的新特性支持,支持Yarn组件在启动Container时使能NUMA感知功能,原理是读取系统物理节点上每个NUMA节点的CPU核、内存容量,使用Numactl命令指定启动container的CPU范围和membind范围,减少跨片访问。
- 安装numactl
yum install numactl.aarch64
- 开启NUMA感知
yarn.nodemanager.numa-awareness.enabled true
yarn.nodemanager.numa-awareness.read-topology true
在组件参数配置已列出。





