
gala-gopher使用手册
gala-gopher作为数据采集模块提供OS级的监控能力,支持动态加 /卸载探针,可无侵入式地集成第三方探针,快速扩展监控范围。
本文介绍如何部署和使用gala-gopher服务。
安装
挂载repo源:
[oe-2309] # openEuler 2309 官方发布源
name=oe2309
baseurl=http://119.3.219.20:82/openEuler:/23.09/standard_x86_64
enabled=1
gpgcheck=0
priority=1
[oe-2309:Epol] # openEuler 2309:Epol 官方发布源
name=oe2309_epol
baseurl=http://119.3.219.20:82/openEuler:/23.09:/Epol/standard_x86_64/
enabled=1
gpgcheck=0
priority=1
安装gala-gopher:
# yum install gala-gopher
配置
配置介绍
gala-gopher配置文件为/opt/gala-gopher/gala-gopher.conf,该文件配置项说明如下(省略无需用户配置的部分)。
如下配置可以根据需要进行修改:
- global:gala-gopher全局配置信息
- log_file_name:gala-gopher日志文件名
- log_level:gala-gopher日志级别(暂未开放此功能)
- pin_path:ebpf探针共享map存放路径(建议维持默认配置)
- metric:指标数据metrics输出方式配置
- out_channel:metrics输出通道,支持配置web_server|logs|kafka,配置为空则输出通道关闭
- kafka_topic:若输出通道为kafka,此为topic配置信息
- event:异常事件event输出方式配置
- out_channel:event输出通道,支持配置logs|kafka,配置为空则输出通道关闭
- kafka_topic:若输出通道为kafka,此为topic配置信息
- timeout:同一异常事件上报间隔设置
- desc_language:异常事件描述信息语言选择,当前支持配置zh_CN|en_US
- meta:元数据metadata输出方式配置
- out_channel:metadata输出通道,支持logs|kafka,配置为空则输出通道关闭
- kafka_topic:若输出通道为kafka,此为topic配置信息
- ingress:探针数据上报相关配置
- interval:暂未使用
- egress:上报数据库相关配置
- interval:暂未使用
- time_range:暂未使用
- imdb:cache缓存规格配置
- max_tables_num:最大的cache表个数,/opt/gala-gopher/meta目录下每个meta对应一个表
- max_records_num:每张cache表最大记录数,通常每个探针在一个观测周期内产生至少1条观测记录
- max_metrics_num:每条观测记录包含的最大的metric指标个数
- record_timeout:cache表老化时间,若cache表中某条记录超过该时间未刷新则删除记录,单位为秒
- web_server:输出通道web_server配置
- port:监听端口
- rest_api_server
- port:RestFul API监听端口
- ssl_auth:设置RestFul API开启https加密以及鉴权,on为开启,off为不开启,建议用户在实际生产环境开启
- private_key:用于RestFul API https加密的服务端私钥文件绝对路径,当ssl_auth为“on”必配
- cert_file:用于RestFul API https加密的服务端证书绝对路径,当ssl_auth为“on”必配
- ca_file:用于RestFul API对客户端进行鉴权的CA中心证书绝对路径,当ssl_auth为“on”必配
- kafka:输出通道kafka配置
- kafka_broker:kafka服务器的IP和port
- batch_num_messages:每个批次发送的消息数量
- compression_codec:消息压缩类型
- queue_buffering_max_messages:生产者缓冲区中允许的最大消息数
- queue_buffering_max_kbytes:生产者缓冲区中允许的最大字节数
- queue_buffering_max_ms:生产者在发送批次之前等待更多消息加入的最大时间
- logs:输出通道logs配置
- metric_dir:metrics指标数据日志路径
- event_dir:异常事件数据日志路径
- meta_dir:metadata元数据日志路径
- debug_dir:gala-gopher运行日志路径
配置文件示例
配置选择数据输出通道:
metric = { out_channel = "web_server"; kafka_topic = "gala_gopher"; }; event = { out_channel = "kafka"; kafka_topic = "gala_gopher_event"; }; meta = { out_channel = "kafka"; kafka_topic = "gala_gopher_metadata"; };配置kafka和webServer:
web_server = { port = 8888; }; kafka = { kafka_broker = "<kafka服务器IP>:9092"; };
启动
配置完成后,执行如下命令启动gala-gopher。
# systemctl start gala-gopher.service
查询gala-gopher服务状态。
# systemctl status gala-gopher.service
若显示结果如下,说明服务启动成功。需要关注开启的探针是否已启动,如果探针线程不存在,请检查配置文件及gala-gopher运行日志文件。
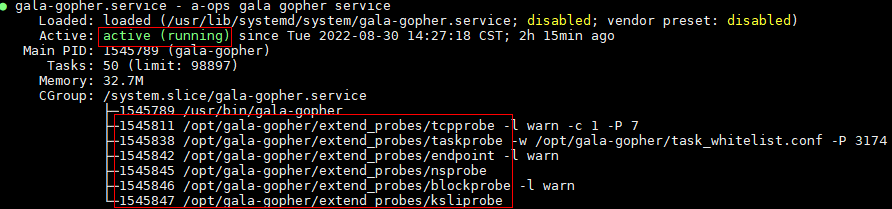
说明:gala-gopher部署和运行均需要root权限。
REST 动态配置接口
WEB server端口可配置(缺省9999),URL组织方式 http://[gala-gopher所在节点ip]:[端口号]/[function(采集特性)],比如火焰图的URL:http://localhost:9999/flamegraph(以下文档均以火焰图举例)。
配置探针监控范围
探针默认关闭,可以通过API动态开启、设置监控范围。以火焰图为例,通过REST分别开启oncpu/offcpu/mem火焰图能力。并且监控范围支持进程ID、进程名、容器ID、POD四个维度来设置。
下面是火焰图同时开启oncpu, offcpu采集特性的API举例:
curl -X PUT http://localhost:9999/flamegraph --data-urlencode json='
{
"cmd": {
"bin": "/opt/gala-gopher/extend_probes/stackprobe",
"check_cmd": "",
"probe": [
"oncpu",
"offcpu"
]
},
"snoopers": {
"proc_id": [
101,
102
],
"proc_name": [
{
"comm": "app1",
"cmdline": "",
"debugging_dir": ""
},
{
"comm": "app2",
"cmdline": "",
"debugging_dir": ""
}
],
"pod_id": [
"pod1",
"pod2"
],
"container_id": [
"container1",
"container2"
]
}
}'
全量采集特性说明如下:
| 采集特性 | 采集特性说明 | 采集子项范围 | 监控对象 | 启动文件 | 启动条件 |
|---|---|---|---|---|---|
| flamegraph | 在线性能火焰图观测能力 | oncpu, offcpu, mem | proc_id, proc_name, pod_id, container_id | $gala-gopher-dir/stackprobe | NA |
| l7 | 应用7层协议观测能力 | l7_bytes_metrics、l7_rpc_metrics、l7_rpc_trace | proc_id, proc_name, pod_id, container_id | $gala-gopher-dir/l7probe | NA |
| tcp | TCP异常、状态观测能力 | tcp_abnormal, tcp_rtt, tcp_windows, tcp_rate, tcp_srtt, tcp_sockbuf, tcp_stats,tcp_delay | proc_id, proc_name, pod_id, container_id | $gala-gopher-dir/tcpprobe | NA |
| socket | Socket(TCP/UDP)异常观测能力 | tcp_socket, udp_socket | proc_id, proc_name, pod_id, container_id | $gala-gopher-dir/endpoint | NA |
| io | Block层I/O观测能力 | io_trace, io_err, io_count, page_cache | NA | $gala-gopher-dir/ioprobe | NA |
| proc | 进程系统调用、I/O、DNS、VFS等观测能力 | base_metrics, proc_syscall, proc_fs, proc_io, proc_dns,proc_pagecache | proc_id, proc_name, pod_id, container_id | $gala-gopher-dir/taskprobe | NA |
| jvm | JVM层GC, 线程, 内存, 缓存等观测能力 | NA | proc_id, proc_name, pod_id, container_id | $gala-gopher-dir/jvmprobe | NA |
| ksli | Redis性能SLI(访问时延)观测能力 | NA | proc_id, proc_name, pod_id, container_id | $gala-gopher-dir/ksliprobe | NA |
| postgre_sli | PG DB性能SLI(访问时延)观测能力 | NA | proc_id, proc_name, pod_id, container_id | $gala-gopher-dir/pgsliprobe | NA |
| opengauss_sli | openGauss访问吞吐量观测能力 | NA | [ip, port, dbname, user,password] | $gala-gopher-dir/pg_stat_probe.py | NA |
| dnsmasq | DNS会话观测能力 | NA | proc_id, proc_name, pod_id, container_id | $gala-gopher-dir/rabbitmq_probe.sh | NA |
| lvs | lvs会话观测能力 | NA | NA | $gala-gopher-dir/trace_lvs | lsmod|grep ip_vs| wc -l |
| nginx | Nginx L4/L7层会话观测能力 | NA | proc_id, proc_name, pod_id, container_id | $gala-gopher-dir/nginx_probe | NA |
| haproxy | Haproxy L4/7层会话观测能力 | NA | proc_id, proc_name, pod_id, container_id | $gala-gopher-dir/trace_haproxy | NA |
| kafka | kafka 生产者/消费者topic观测能力 | NA | dev, port | $gala-gopher-dir/kafkaprobe | NA |
| baseinfo | 系统基础信息 | cpu, mem, nic, disk, net, fs, proc,host | proc_id, proc_name, pod_id, container_id | system_infos | NA |
| virt | 虚拟化管理信息 | NA | NA | virtualized_infos | NA |
| tprofiling | 线程级性能profiling观测能力 | oncpu, syscall_file, syscall_net, syscall_lock, syscall_sched | proc_id, proc_name, pod_id, container_id | $gala-gopher-dir/tprofiling | NA |
| container | 容器信息 | NA | proc_id, proc_name, container_id | $gala-gopher-dir/cadvisor_probe.py | NA |
配置探针运行参数
探针在运行期间还需要设置一些参数设置,例如:设置火焰图的采样周期、上报周期。
curl -X PUT http://localhost:9999/flamegraph --data-urlencode json='
{
"params": {
"report_period": 180,
"sample_period": 180,
"metrics_type": [
"raw",
"telemetry"
]
}
}'
详细参数运行参数如下:
| 参数 | 含义 | 缺省值&范围 | 单位 | 支持的监控范围 | gala-gopher是否支持 |
|---|---|---|---|---|---|
| sample_period | 采样周期 | 5000, [100~10000] | ms | io, tcp | Y |
| report_period | 上报周期 | 60, [5~600] | s | ALL | Y |
| latency_thr | 时延上报门限 | 0, [10~100000] | ms | tcp, io, proc, ksli | Y |
| offline_thr | 进程离线上报门限 | 0, [10~100000] | ms | proc | Y |
| drops_thr | 丢包上送门限 | 0, [10~100000] | package | tcp, nic | Y |
| res_lower_thr | 资源百分比下限 | 0%, [0%~100%] | percent | ALL | Y |
| res_upper_thr | 资源百分比上限 | 0%, [0%~100%] | percent | ALL | Y |
| report_event | 上报异常事件 | 0, [0, 1] | NA | ALL | Y |
| metrics_type | 上报telemetry metrics | raw, [raw, telemetry] | NA | ALL | N |
| env | 工作环境类型 | node, [node, container, kubenet] | NA | ALL | N |
| report_source_port | 是否上报源端口 | 0, [0, 1] | NA | tcp | Y |
| l7_protocol | L7层协议范围 | http, [http, pgsql, mysql, redis, kafka, mongo, rocketmq, dns] | NA | l7 | Y |
| support_ssl | 支持SSL加密协议观测 | 0, [0, 1] | NA | l7 | Y |
| multi_instance | 是否每个进程输出独立火焰图 | 0, [0, 1] | NA | flamegraph | Y |
| native_stack | 是否显示本地语言堆栈(针对JAVA进程) | 0, [0, 1] | NA | flamegraph | Y |
| cluster_ip_backend | 执行Cluster IP backend转换 | 0, [0, 1] | NA | tcp,l7 | Y |
| pyroscope_server | 设置火焰图UI服务端地址 | localhost:4040 | NA | flamegraph | Y |
| svg_period | 火焰图svg文件生成周期 | 180, [30, 600] | s | flamegraph | Y |
| perf_sample_period | oncpu火焰图采集堆栈信息的周期 | 10, [10, 1000] | ms | flamegraph | Y |
| svg_dir | 火焰图svg文件存储目录 | "/var/log/gala-gopher/stacktrace" | NA | flamegraph | Y |
| flame_dir | 火焰图原始堆栈信息存储目录 | "/var/log/gala-gopher/flamegraph" | NA | flamegraph | Y |
| dev_name | 观测的网卡/磁盘设备名 | "" | NA | io, kafka, ksli, postgre_sli,baseinfo, tcp | Y |
| continuous_sampling | 是否持续采样 | 0, [0, 1] | NA | ksli | Y |
| elf_path | 要观测的可执行文件的路径 | "" | NA | nginx, haproxy, dnsmasq | Y |
| kafka_port | 要观测的kafka端口号 | 9092, [1, 65535] | NA | kafka | Y |
| cadvisor_port | 启动的cadvisor端口号 | 8080, [1, 65535] | NA | cadvisor | Y |
启动、停止探针
curl -X PUT http://localhost:9999/flamegraph --data-urlencode json='
{
"state": "running" // optional: running,stopped
}'
约束与限制说明
- 接口为无状态形式,每次上传的设置为该探针的最终运行结果,包括状态、参数、监控范围。
- 监控对象可以任意组合,监控范围取合集。
- 启动文件必须真实有效。
- 采集特性可以按需开启全部/部分能力,关闭时只能整体关闭某个采集特性。
- opengauss监控对象是DB实例(IP/Port/dbname/user/password)。
- 接口每次最多接收2048长度的数据。
获取探针配置与运行状态
curl -X GET http://localhost:9999/flamegraph
{
"cmd": {
"bin": "/opt/gala-gopher/extend_probes/stackprobe",
"check_cmd": ""
"probe": [
"oncpu",
"offcpu"
]
},
"snoopers": {
"proc_id": [
101,
102
],
"proc_name": [
{
"comm": "app1",
"cmdline": "",
"debugging_dir": ""
},
{
"comm": "app2",
"cmdline": "",
"debugging_dir": ""
}
],
"pod_id": [
"pod1",
"pod2"
],
"container_id": [
"container1",
"container2"
]
},
"params": {
"report_period": 180,
"sample_period": 180,
"metrics_type": [
"raw",
"telemetry"
]
},
"state": "running"
}
stackprobe 介绍
适用于云原生环境的性能火焰图。
特性
支持观测C/C++、Go、Rust、Java语言应用。
调用栈支持容器、进程粒度:对于容器内进程,在调用栈底部分别以[Pod]和[Con]前缀标记工作负载Pod名称、容器Container名称。进程名以[
]前缀标识,线程及函数(方法)无前缀。 支持本地生成svg格式火焰图或上传调用栈数据到中间件。
支持依照进程粒度多实例生成/上传火焰图。
对于Java进程的火焰图,支持同时显示本地方法和Java方法。
支持oncpu/offcpu/mem等多类型火焰图。
支持自定义采样周期。
使用说明
启动命令示例(基本):使用默认参数启动性能火焰图。
curl -X PUT http://localhost:9999/flamegraph -d json='{ "cmd": {"probe": ["oncpu"] }, "snoopers": {"proc_name": [{ "comm": "cadvisor"}] }, "state": "running"}'
启动命令示例(进阶):使用自定义参数启动性能火焰图。完整可配置参数列表参见配置探针运行参数。
curl -X PUT http://localhost:9999/flamegraph -d json='{ "cmd": { "check_cmd": "", "probe": ["oncpu", "offcpu", "mem"] }, "snoopers": { "proc_name": [{ "comm": "cadvisor", "cmdline": "", "debugging_dir": "" }, { "comm": "java", "cmdline": "", "debugging_dir": "" }] }, "params": { "perf_sample_period": 100, "svg_period": 300, "svg_dir": "/var/log/gala-gopher/stacktrace", "flame_dir": "/var/log/gala-gopher/flamegraph", "pyroscope_server": "localhost:4040", "multi_instance": 1, "native_stack": 0 }, "state": "running"}'
下面说明主要配置项:
设置开启的火焰图类型
通过probe参数设置,参数值为
oncpu,offcpu,mem,分别代表进程cpu占用时间,进程被阻塞时间,进程申请内存大小的统计。示例:
"probe": ["oncpu", "offcpu", "mem"]设置生成本地火焰图svg文件的周期
通过svg_period参数设置,单位为秒,默认值180,可选设置范围为[30, 600]的整数。
示例:
"svg_period": 300开启/关闭堆栈信息上传到pyroscope
通过pyroscope_server参数设置,参数值需要包含addr和port,参数为空或格式错误则探针不会尝试上传堆栈信息。
上传周期30s。
示例:
"pyroscope_server": "localhost:4040"设置调用栈采样周期
通过perf_sample_period设置,单位为毫秒,默认值10,可选设置范围为[10, 1000]的整数,此参数仅对oncpu类型的火焰图有效。
示例:
"perf_sample_period": 100开启/关闭多实例生成火焰图
通过multi_instance设置,参数值为0或1,默认值为0。值为0表示所有进程的火焰图会合并在一起,值为1表示分开生成每个进程的火焰图。
示例:
"multi_instance": 1开启/关闭本地调用栈采集
通过native_stack设置,参数值为0或1,默认值为0。此参数仅对JAVA进程有效。值为0表示不采集JVM自身的调用栈,值为1表示采集JVM自身的调用栈。
示例:
"native_stack": 1显示效果:(左"native_stack": 1,右"native_stack": 0)
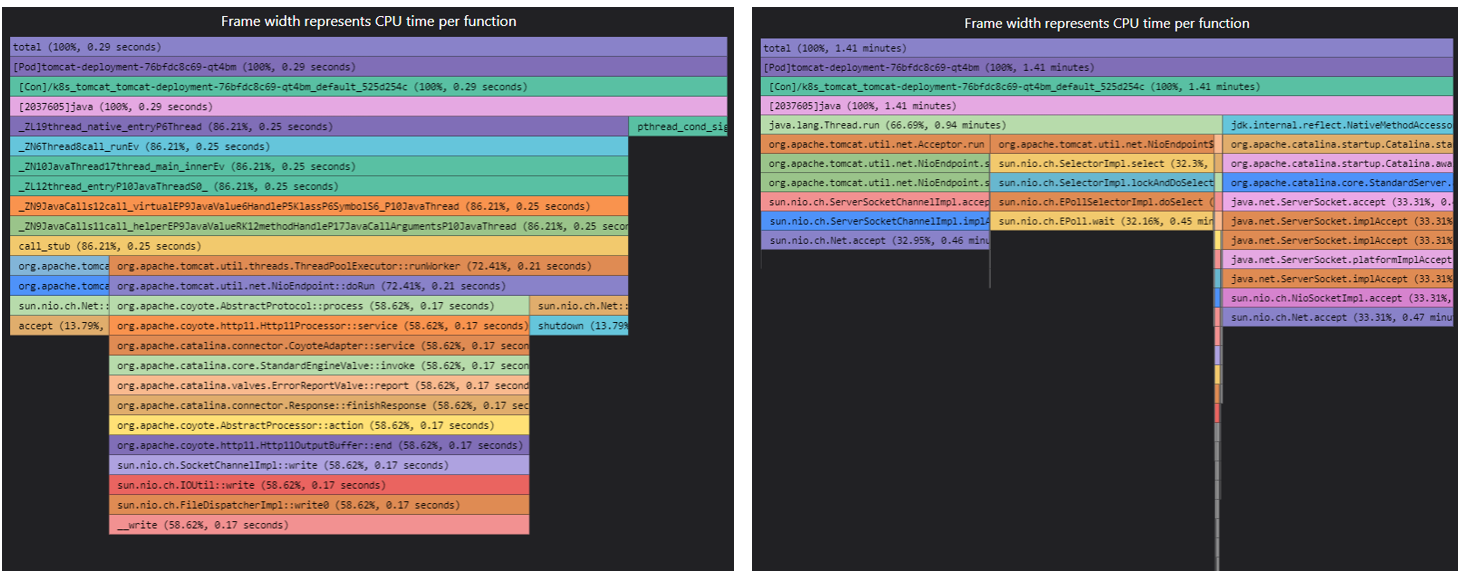
实现方案
1. 用户态程序逻辑
周期性地(30s)根据符号表将内核态上报的堆栈信息从地址转换为符号。然后使用flamegraph插件或pyroscope将符号化的调用栈转换为火焰图。
其中,对于代码段类型获取符号表的方法不同。
内核符号表获取:读取/proc/kallsyms。
本地语言符号表获取:查询进程的虚拟内存映射文件(/proc/{pid}/maps),获取进程内存中各个代码段的地址映射,然后利用libelf库加载每个代码段对应模块的符号表。
Java语言符号表获取:
由于 Java 方法没有静态映射到进程的虚拟地址空间,因此我们采用其他方式获取符号化的Java调用栈。
方式一:perf观测
通过往Java进程加载JVM agent动态库来跟踪JVM的方法编译加载事件,获取并记录内存地址到Java符号的映射,从而实时生成Java进程的符号表。这种方法需要Java进程开启-XX:+PreserveFramePointer启动参数。本方式的优点是火焰图中可显示JVM自身的调用栈,而且这种方式生成的Java火焰图可以和其他进程的火焰图合并显示。
方式二:JFR观测
通过动态开启JVM内置分析器JFR来跟踪Java应用程序的各种事件和指标。开启JFR的方式为往Java进程加载Java agent,Java agent中会调用JFR API。本方式的优点是对Java方法调用栈的采集会更加准确详尽。
上述两种针对Java进程的性能分析方法都可以实时加载(不需要重启Java进程)且具有低底噪的优点。当stackprobe的启动参数为"multi_instance": 1且"native_stack": 0时,stackprobe会使用方法二生成Java进程火焰图,否则会使用方法一。
2. 内核态程序逻辑
内核态基于eBPF实现。不同火焰图类型对应不同的eBPF程序。eBPF程序会周期性地或通过事件触发的方式遍历当前用户态和内核态的调用栈,并上报用户态。
2.1 oncpu火焰图
在perf SW事件PERF_COUNT_SW_CPU_CLOCK上挂载采样eBPF程序,周期性采样调用栈。
2.2 offcpu火焰图
在进程调度的tracepoint(sched_switch)上挂载采样eBPF程序,采样eBPF程序中记录进程被调度出去时间和进程id,在进程被调度回来时采样调用栈。
2.3 mem火焰图
在缺页异常的tracepoint(page_fault_user)上挂载采样eBPF程序,事件触发时采样调用栈。
3. Java语言支持
stackprobe主进程:
Java代理加载模块
发现新增java进程则将JVM代理程序复制到该进程空间下/proc/<pid>/root/tmp(因为attach时容器内JVM需要可见此代理程序)。
设置上述目录和JVM代理程序的owner和被观测java进程一致。
启动jvm_attach子进程,并传入被观测java进程相关参数。
JVM代理程序
jvm_agent.so:注册JVMTI回调函数
当JVM加载一个Java方法或者动态编译一个本地方法时JVM会调用回调函数,回调函数会将java类名和方法名以及对应的内存地址写入到被观测java进程空间下(/proc/<pid>/root/tmp/java-data-<pid>/java-symbols.bin)。
JstackProbeAgent.jar:调用JFR API
开启持续30s的JFR功能,并转换JFR统计结果为火焰图可用的堆栈格式,结果输出到到被观测java进程空间下(/proc/<pid>/root/tmp/java-data-<pid>/stacks-<flame_type>.txt)。详见JstackProbe简介。
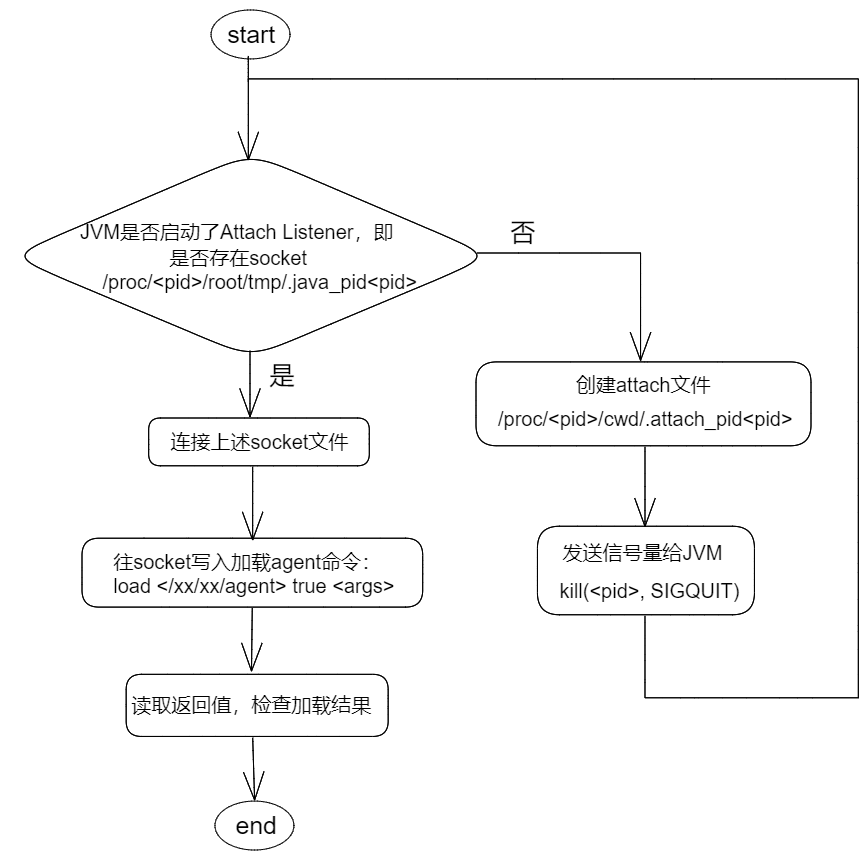
jvm_attach:用于实时加载JVM代理程序到被观测进程的JVM上 (参考jdk源码中sun.tools.attach.LinuxVirtualMachine和jattach工具)。
设置自身的namespace(JVM加载agent时要求加载进程和被观测进程的namespace一致)。
检查JVM attach listener是否启动(是否存在UNIX socket文件:/proc/<pid>/root/tmp/.java_pid<pid>)。
未启动则创建/proc/<pid>/cwd/.attach_pid<pid>,并发送SIGQUIT信号给JVM。
连接UNIX socket。
读取响应为0表示attach成功。
attach agent流程图示:
注意事项
- 对于Java应用的观测,为获取最佳观测效果,请设置stackprobe启动选项为"multi_instance": 1, "native_stack": 0来使能JFR观测(JDK8u262+)。否则stackprobe会以perf方式来生成Java火焰图。perf方式下,请开启JVM选项XX:+PreserveFramePointer(JDK8以上)。
约束条件
- 支持基于hotspot JVM的Java应用观测。
tprofiling 介绍
tprofiling 是 gala-gopher 提供的一个基于 ebpf 的线程级应用性能诊断工具,它使用 ebpf 技术观测线程的关键系统性能事件,并关联丰富的事件内容,从而实时地记录线程的运行状态和关键行为,帮助用户快速识别应用性能问题。
功能特性
从操作系统的视角来看,一个运行的应用程序是由多个进程组成,每个进程是由多个运行的线程组成。tprofiling 通过观测这些线程运行过程中执行的一些关键行为(后面称之为事件)并记录下来,然后在前端界面以时间线的方式进行展示,进而就可以很直观地分析这些线程在某段时间内正在做什么,是在 CPU 上执行还是阻塞在某个文件、网络操作上。当应用程序出现性能问题时,通过分析对应线程的关键性能事件的执行序列,快速地进行定界定位。
基于当前已实现的事件观测范围, tprofiling 能够定位的应用性能问题场景主要包括:
- 文件 I/O 耗时、阻塞问题
- 网络 I/O 耗时、阻塞问题
- 锁竞争问题
- 死锁问题
随着更多类型的事件不断地补充和完善,tprofiling 将能够覆盖更多类型的应用性能问题场景。
事件观测范围
tprofiling 当前支持的系统性能事件包括两大类:系统调用事件和 oncpu 事件。
系统调用事件
应用性能问题通常是由于系统资源出现瓶颈导致,比如 CPU 资源占用过高、I/O 资源等待。应用程序往往通过系统调用访问这些系统资源,因此可以对关键的系统调用事件进行观测来识别耗时、阻塞的资源访问操作。
tprofiling 当前已观测的系统调用事件参见章节: 支持的系统调用事件 ,大致分为几个类型:文件操作(file)、网络操作(net)、锁操作(lock)和调度操作(sched)。下面列出部分已观测的系统调用事件:
- 文件操作(file)
- read/write:读写磁盘文件或网络,可能会耗时、阻塞。
- sync/fsync:对文件进行同步刷盘操作,完成前线程会阻塞。
- 网络操作(net)
- send/recv:读写网络,可能会耗时、阻塞。
- 锁操作(lock)
- futex:用户态锁实现相关的系统调用,触发 futex 往往意味出现锁竞争,线程可能进入阻塞状态。
- 调度操作(sched):这里泛指那些可能会引起线程状态变化的系统调用事件,如线程让出 cpu 、睡眠、或等待其他线程等。
- nanosleep:线程进入睡眠状态。
- epoll_wait:等待 I/O 事件到达,事件到达之前线程会阻塞。
oncpu 事件
此外,根据线程是否在 CPU 上运行可以将线程的运行状态分为两种:oncpu 和 offcpu ,前者表示线程正在 CPU 上运行,后者表示线程不在 CPU 上运行。通过观测线程的 oncpu 事件,可以识别线程是否正在执行耗时的 cpu 操作。
事件内容
线程 profiling 事件主要包括以下几部分内容。
事件来源信息:包括事件所属的线程ID、线程名、进程ID、进程名、容器ID、容器名、主机ID、主机名等信息。
thread.pid:事件所属的线程ID。thread.comm:事件所属的线程名。thread.tgid:事件所属的进程ID。proc.name:事件所属的进程名。container.id:事件所属的容器ID。container.name:事件所属的容器名。host.id:事件所属的主机ID。host.name:事件所属的主机名。
事件属性信息:包括公共的事件属性和扩展的事件属性。
公共的事件属性:包括事件名、事件类型、事件开始时间、事件结束时间、事件执行时间等。
event.name:事件名。event.type:事件类型,目前支持 oncpu、file、net、lock、sched 五种。start_time:事件开始时间,聚合事件中第一个事件的开始时间,关于聚合事件的说明参见章节:聚合事件 。end_time:事件结束时间,聚合事件中最后一个事件的结束时间。duration:事件执行时间,值为(end_time - start_time)。count:事件聚合数量。
扩展的事件属性:针对不同的系统调用事件,补充更加丰富的事件内容。如 read/write 文件或网络时,提供文件路径、网络连接以及函数调用栈等信息。
func.stack:事件的函数调用栈信息。file.path:文件类事件的文件路径信息。sock.conn:网络类事件的tcp连接信息。futex.op:futex系统调用事件的操作类型,取值为 wait 或 wake 。
不同事件类型支持的扩展事件属性的详细情况参见章节:支持的系统调用事件 。
事件输出
tprofiling 作为 gala-gopher 提供的一个扩展的 ebpf 探针程序,产生的系统事件会发送至 gala-gopher 处理,并由 gala-gopher 按照开源的 openTelemetry 事件格式对外输出,并通过 json 格式发送到 kafka 消息队列中。前端可以通过对接 kafka 消费 tprofiling 事件。
下面是线程 profiling 事件的一个输出示例:
{
"Timestamp": 1661088145000,
"SeverityText": "INFO",
"SeverityNumber": 9,
"Body": "",
"Resource": {
"host.id": "",
"host.name": "",
"thread.pid": 10,
"thread.tgid": 10,
"thread.comm": "java",
"proc.name": "xxx.jar",
"container.id": "",
"container.name": "",
},
"Attributes": {
values: [
{
// common info
"event.name": "read",
"event.type": "file",
"start_time": 1661088145000,
"end_time": 1661088146000,
"duration": 0.1,
"count": 1,
// extend info
"func.stack": "read;",
"file.path": "/test.txt"
},
{
"event.name": "oncpu",
"event.type": "oncpu",
"start_time": 1661088146000,
"end_time": 1661088147000,
"duration": 0.1,
"count": 1,
}
]
}
}
部分字段说明:
Timestamp:事件上报的事件点。Resource:包括事件来源信息。Attributes:包括事件属性信息,它包含一个values列表字段,列表中的每一项表示一个属于相同来源的 tprofiling 事件,其中包含该事件的属性信息。
快速开始
安装部署
tprofiling 是 gala-gopher 提供的一个扩展的 ebpf 探针程序,因此,需要先安装部署好 gala-gopher 软件,然后再开启 tprofiling 功能。
另外,为了能够在前端用户界面使用 tprofiling 的能力,gala-ops 基于开源的 kafka + logstash + elasticsearch + grafana 可观测软件搭建了用于演示的 tprofiling 功能的用户界面,用户可以使用 gala-ops 提供的部署工具进行快速部署。
运行架构
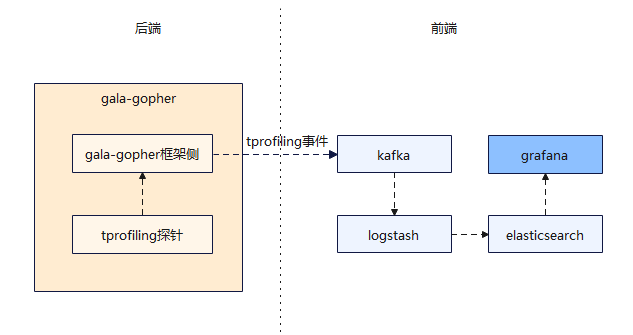
前端软件说明:
- kafka:一个开源的消息队列中间件,用于接收并存储 gala-gopher 采集的 tprofiling 事件。
- logstash:一个实时的开源日志收集引擎,用于从 kafka 消费 tprofiling 事件,经过过滤、转换等处理后发送至 elasticsearch 。
- elasticsearch:一个开放的分布式搜索和分析引擎,用于储存经过处理后的 tprofiling 事件,供 grafana 查询和可视化展示。
- grafana:一个开源的可视化工具,用于查询并可视化展示采集的 tprofiling 事件。用户最终通过 grafana 提供的用户界面来使用 tprofiling 的功能,分析应用性能问题。
部署 tprofiling 探针
用户需要先安装好 gala-gopher,具体的安装部署说明可参考 gala-gopher文档 。由于 tprofiling 事件会发送到 kafka 中,因此部署时需要配置好 kafka 的服务地址。
安装并运行 gala-gopher 后,使用 gala-gopher 提供的基于 HTTP 的动态配置接口启动 tprofiling 探针。
curl -X PUT http://<gopher-node-ip>:9999/tprofiling -d json='{"cmd": {"probe": ["oncpu", "syscall_file", "syscall_net", "syscall_sched", "syscall_lock"]}, "snoopers": {"proc_name": [{"comm": "java"}]}, "state": "running"}'
配置参数说明:
<gopher-node-ip>:部署 gala-gopher 的节点 IP。probe:cmd下的probe配置项指定了 tprofiling 探针观测的系统事件范围。其中,oncpu、syscall_file、syscall_net、syscall_sched、syscall_lock 分别对应 oncpu 事件、以及 file、net、sched、lock 四类系统调用事件。用户可根据需要只开启部分 tprofiling 事件类型的观测。proc_name:snoopers下的proc_name配置项用于过滤要观测的进程名。另外也可以通过proc_id配置项来过滤要观测的进程ID,详情参考:REST 动态配置接口。
要关闭 tprofiling 探针,执行如下命令:
curl -X PUT http://<gopher-node-ip>:9999/tprofiling -d json='{"state": "stopped"}'
部署前端软件
使用 tprofiling 功能的用户界面需要用到的软件包括:kafka、logstash、elasticsearch、grafana。这些软件安装在管理节点,用户可以使用 gala-ops 提供的部署工具进行快速安装部署,参考:在线部署文档。
在管理节点上,通过 在线部署文档 获取部署脚本后,执行如下命令一键安装中间件:kafka、logstash、elasticsearch。
sh deploy.sh middleware -K <部署节点管理IP> -E <部署节点管理IP> -A -p
执行如下命令一键安装 grafana 。
sh deploy.sh grafana -P <Prometheus服务器地址> -E <es服务器地址>
使用
完成上述部署动作后,即可通过浏览器访问 http://[部署节点管理IP]:3000 登录 grafana 来使用 A-Ops,登录用户名、密码默认均为 admin。
登录 grafana 界面后,找到名为 ThreadProfiling 的 dashboard。
点击进入 tprofiling 功能的前端界面,接下来就可以探索 tprofiling 的功能了。
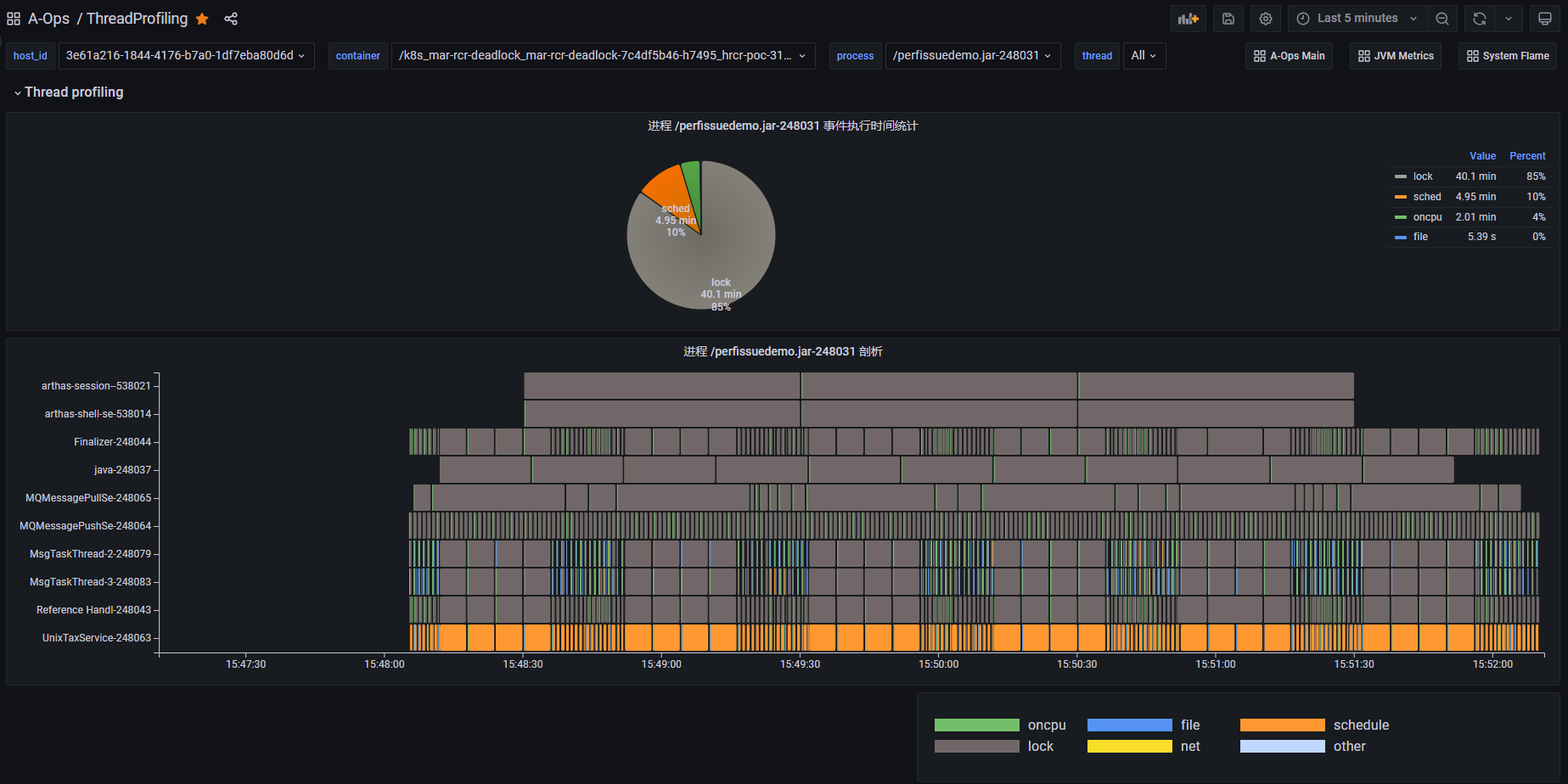
使用案例
案例1:死锁问题定位
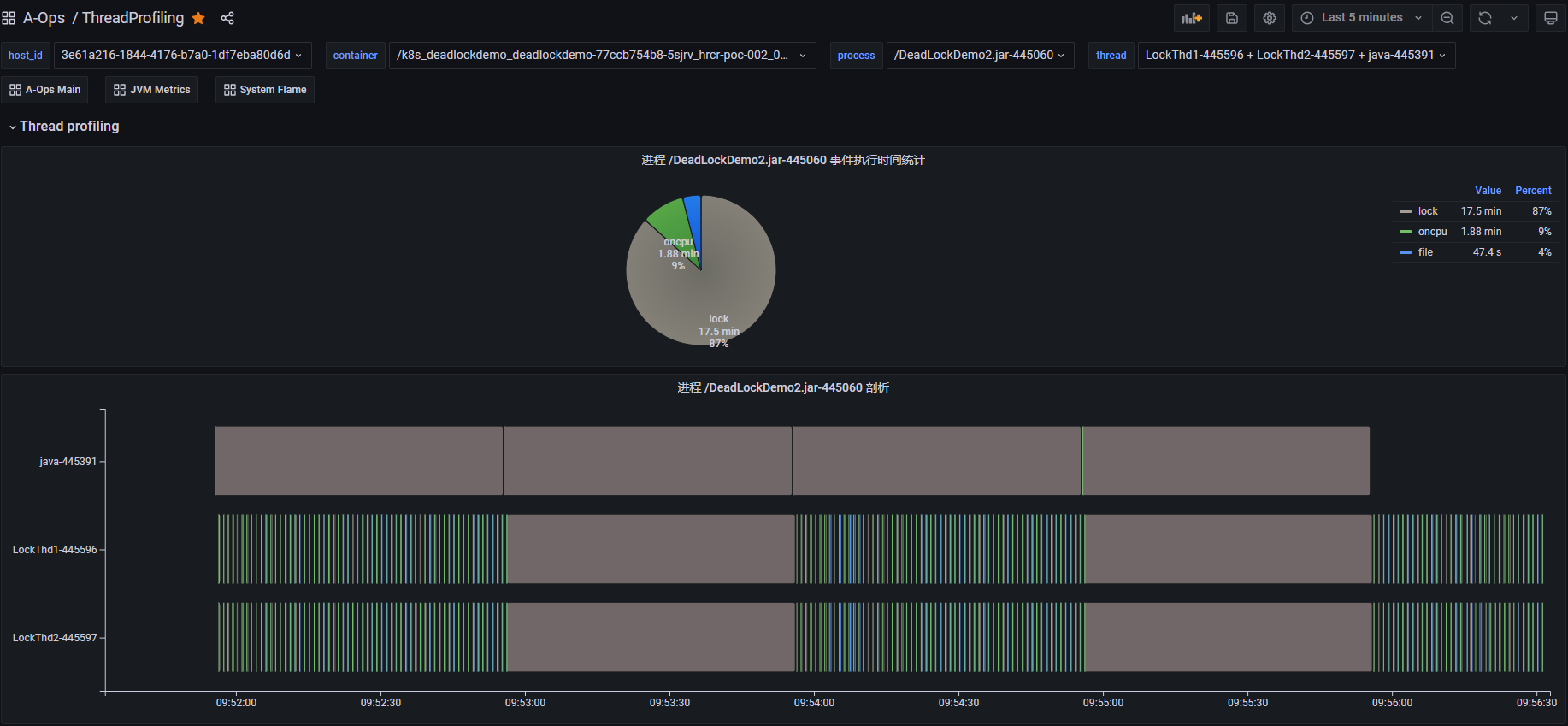
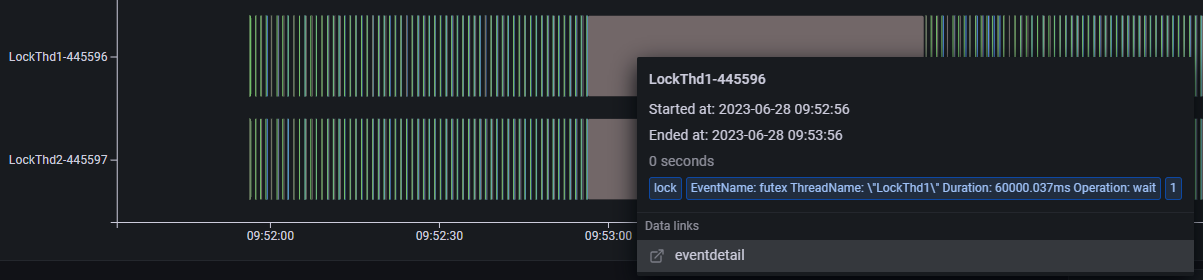
上图是一个死锁 Demo 进程的线程 profiling 运行结果,从饼图中进程事件执行时间的统计结果可以看到,这段时间内 lock 类型事件(灰色部分)占比比较高。下半部分是整个进程的线程 profiling 展示结果,纵轴展示了进程内不同线程的 profiling 事件的执行序列。其中,线程 java 为主线程一直处于阻塞状态,业务线程 LockThd1 和 LockThd2 在执行一些 oncpu 事件和 file 类事件后会间歇性的同时执行一段长时间的 lock 类事件。将光标悬浮到 lock 类型事件上可以查看事件内容,(如下图所示)它触发了 futex 系统调用事件,执行时间为 60 秒。
基于上述观测,我们可以发现业务线程 LockThd1 和 LockThd2 可能存在异常行为。接下来,我们可以进入线程视图,查看这两个业务线程 LockThd1 和 LockThd2 的线程 profiling 结果。
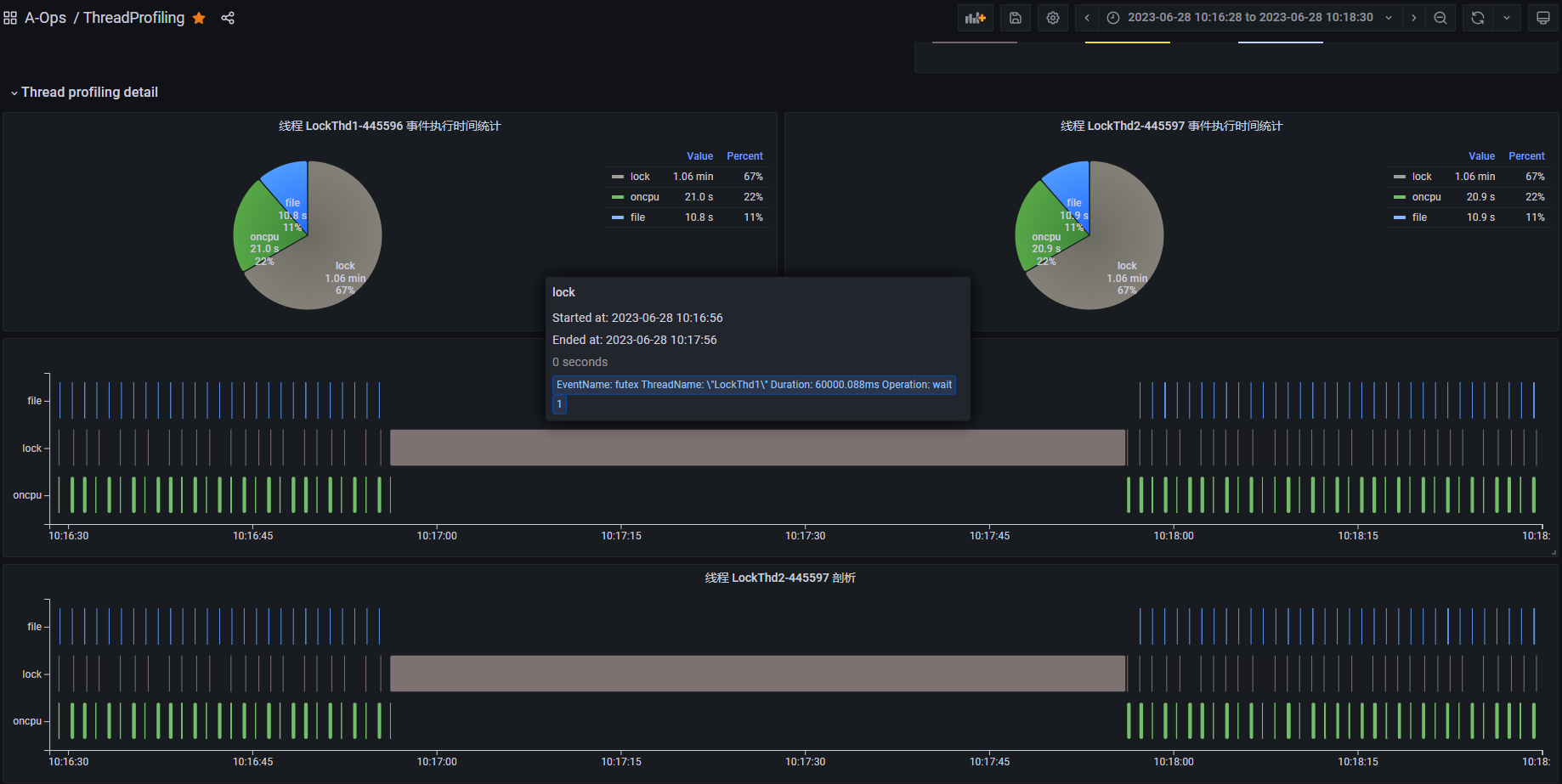
上图是每个线程的 profiling 结果展示,纵轴展示线程内不同事件类型的执行序列。从图中可以看到,线程 LockThd1 和 LockThd2 正常情况下会定期执行 oncpu 事件,其中包括执行一些 file 类事件和 lock 类事件。但是在某个时间点(10:17:00附近)它们会同时执行一个长时间的 lock 类型的 futex 事件,而且这段时间内都没有 oncpu 事件发生,说明它们都进入了阻塞状态。futex 是用户态锁实现相关的系统调用,触发 futex 往往意味出现锁竞争,线程可能进入阻塞状态。
基于上述分析,线程 LockThd1 和 LockThd2 很可能是出现了死锁问题。
案例2:锁竞争问题定位
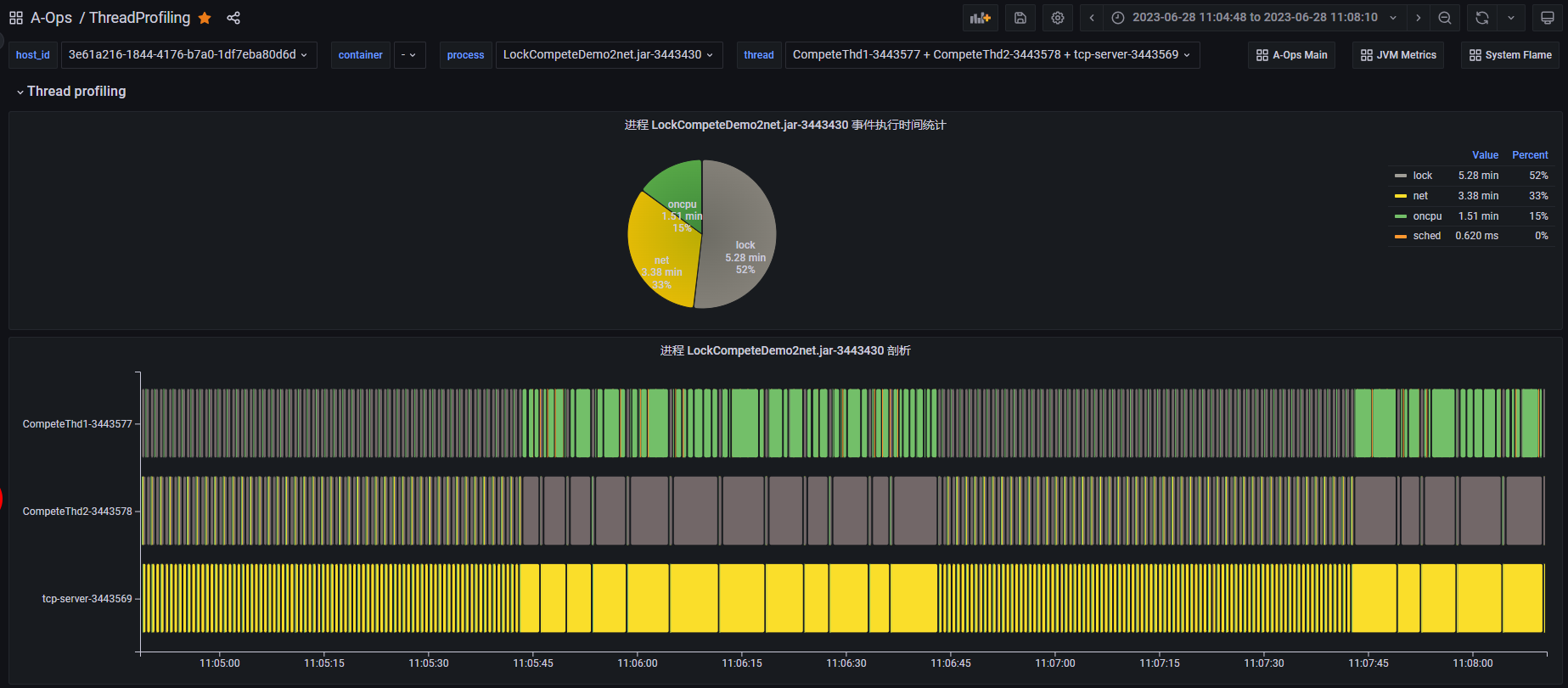
上图是一个锁竞争 Demo 进程的线程 profiling 运行结果。从图中可以看到,该进程在这段时间内主要执行了 lock、net、oncpu 三类事件,该进程包括 3 个运行的业务线程。在11:05:45 - 11:06:45 这段时间内,我们发现这 3 个业务线程的事件执行时间都变得很长了,这里面可能存在性能问题。同样,我们进入线程视图,查看每个线程的线程 profiling 结果,同时我们将时间范围缩小到可能有异常的时间点附近。
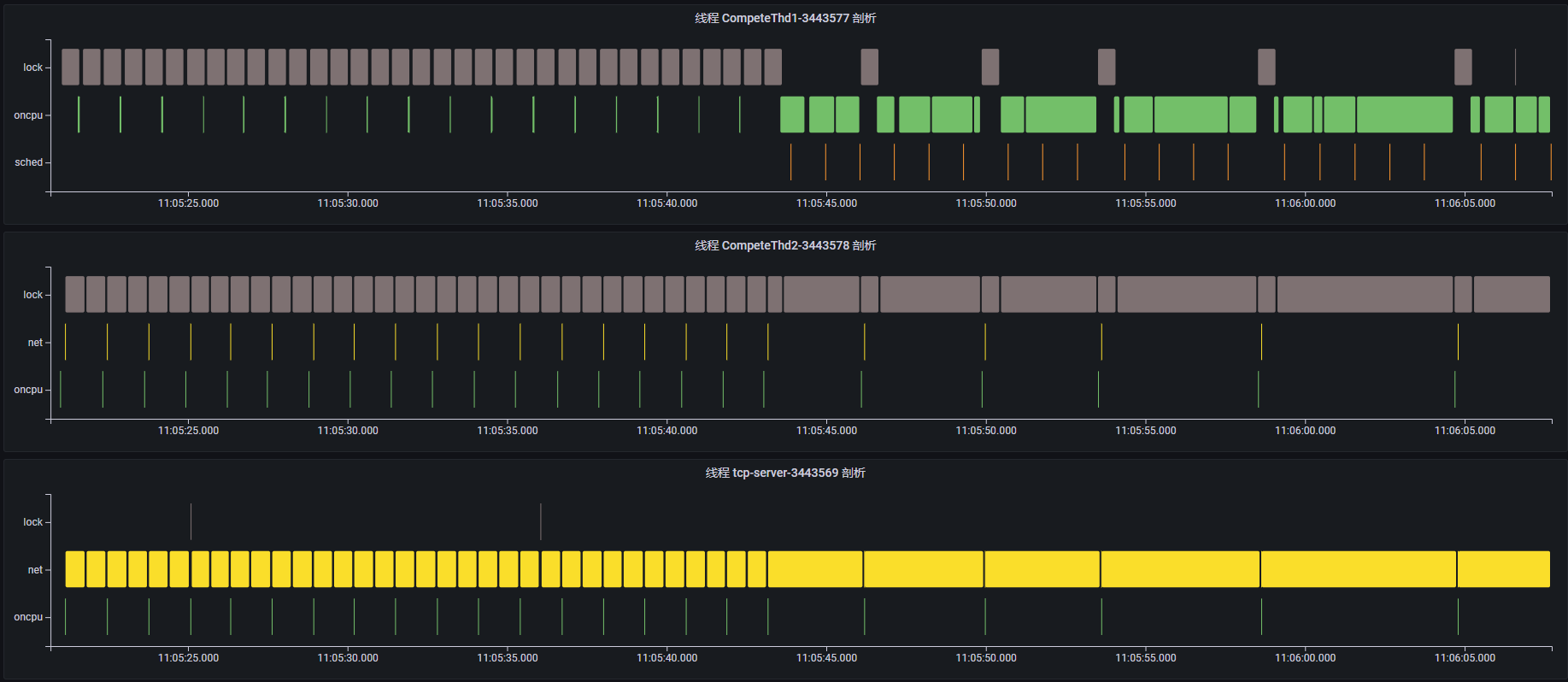
通过查看每个线程的事件执行序列,可以大致了解每个线程这段时间在执行什么功能。
线程 CompeteThd1:每隔一段时间触发短时的 oncpu 事件,执行一次计算任务;但是在 11:05:45 时间点附近开始触发长时的 oncpu 事件,说明正在执行耗时的计算任务。

线程 CompeteThd2:每隔一段时间触发短时的 net 类事件,点击事件内容可以看到,该线程正在通过 write 系统调用发送网络消息,且可以看到对应的 tcp 连接信息;同样在 11:05:45 时间点附近开始执行长时的 futex 事件并进入阻塞状态,此时 write 网络事件的执行间隔变长了。


线程 tcp-server:tcp 服务器,不断通过 read 系统调用读取客户端发送的请求;同样在 11:05:45 时间点附近开始,read 事件执行时间变长,说明此时正在等待接收网络请求。
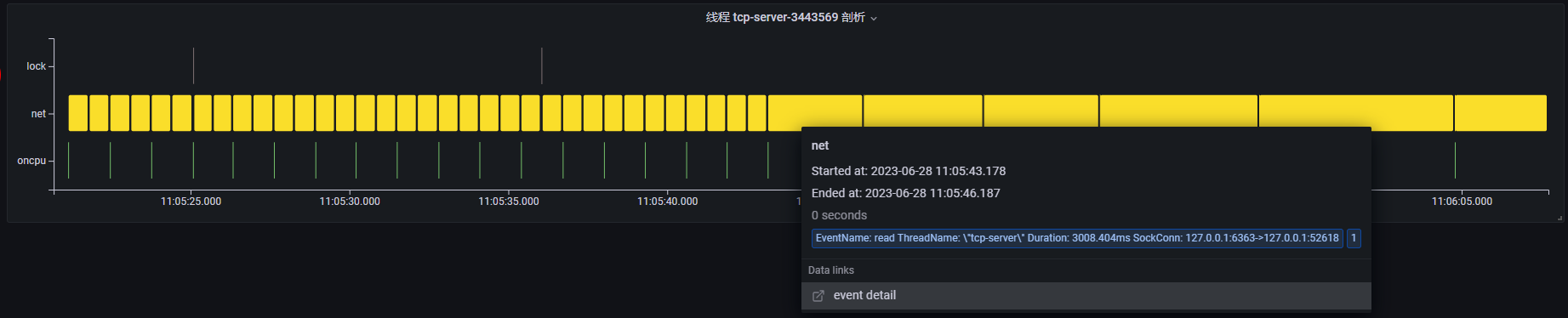
基于上述分析,我们可以发现,每当线程 CompeteThd1 在执行耗时较长的 oncpu 操作时,线程 CompeteThd2 都会调用 futex 系统调用进入阻塞状态,一旦线程 CompeteThd1 完成 oncpu 操作时,线程 CompeteThd2 将获取 cpu 并执行网络 write 操作。因此,大概率是因为线程 CompeteThd1 和线程 CompeteThd2 之间存在锁竞争的问题。而线程 tcp-server 与线程 CompeteThd2 之间存在 tcp 网络通信,由于线程 CompeteThd2 等待锁资源无法发送网络请求,从而导致线程 tcp-server 大部分时间都在等待 read 网络请求。
topics
支持的系统调用事件
选择需要加入观测的系统调用事件的基本原则为:
- 选择可能会比较耗时、阻塞的事件(如文件操作、网络操作、锁操作等),这类事件通常涉及对系统资源的访问。
- 选择影响线程运行状态的事件。
| 事件名/系统调用名 | 描述 | 默认的事件类型 | 扩展的事件内容 |
|---|---|---|---|
| read | 读写磁盘文件或网络,线程可能会耗时、阻塞 | file | file.path, sock.conn, func.stack |
| write | 读写磁盘文件或网络,线程可能会耗时、阻塞 | file | file.path, sock.conn, func.stack |
| readv | 读写磁盘文件或网络,线程可能会耗时、阻塞 | file | file.path, sock.conn, func.stack |
| writev | 读写磁盘文件或网络,线程可能会耗时、阻塞 | file | file.path, sock.conn, func.stack |
| preadv | 读写磁盘文件或网络,线程可能会耗时、阻塞 | file | file.path, sock.conn, func.stack |
| pwritev | 读写磁盘文件或网络,线程可能会耗时、阻塞 | file | file.path, sock.conn, func.stack |
| sync | 对文件进行同步刷盘操作,完成前线程会阻塞 | file | func.stack |
| fsync | 对文件进行同步刷盘操作,完成前线程会阻塞 | file | file.path, sock.conn, func.stack |
| fdatasync | 对文件进行同步刷盘操作,完成前线程会阻塞 | file | file.path, sock.conn, func.stack |
| sched_yield | 线程主动让出 CPU 重新进行调度 | sched | func.stack |
| nanosleep | 线程进入睡眠状态 | sched | func.stack |
| clock_nanosleep | 线程进入睡眠状态 | sched | func.stack |
| wait4 | 线程阻塞 | sched | func.stack |
| waitpid | 线程阻塞 | sched | func.stack |
| select | 无事件到达时线程会阻塞等待 | sched | func.stack |
| pselect6 | 无事件到达时线程会阻塞等待 | sched | func.stack |
| poll | 无事件到达时线程会阻塞等待 | sched | func.stack |
| ppoll | 无事件到达时线程会阻塞等待 | sched | func.stack |
| epoll_wait | 无事件到达时线程会阻塞等待 | sched | func.stack |
| sendto | 读写网络时,线程可能会耗时、阻塞 | net | sock.conn, func.stack |
| recvfrom | 读写网络时,线程可能会耗时、阻塞 | net | sock.conn, func.stack |
| sendmsg | 读写网络时,线程可能会耗时、阻塞 | net | sock.conn, func.stack |
| recvmsg | 读写网络时,线程可能会耗时、阻塞 | net | sock.conn, func.stack |
| sendmmsg | 读写网络时,线程可能会耗时、阻塞 | net | sock.conn, func.stack |
| recvmmsg | 读写网络时,线程可能会耗时、阻塞 | net | sock.conn, func.stack |
| futex | 触发 futex 往往意味着出现锁等待,线程可能进入阻塞状态 | lock | futex.op, func.stack |
聚合事件
tprofiling 当前支持的系统性能事件包括两大类:系统调用事件和 oncpu 事件。其中,oncpu 事件以及部分系统调用事件(比如read/write)在特定的应用场景下可能会频繁触发,从而产生大量的系统事件,这会对观测的应用程序性能以及 tprofiling 探针本身的性能造成较大的影响。
为了优化性能,tprofiling 将一段时间内(1s)属于同一个线程的具有相同事件名的多个系统事件聚合为一个事件进行上报。因此,一个 tprofiling 事件实际上指的是一个聚合事件,它包含一个或多个相同的系统事件。相比于一个真实的系统事件,一个聚合事件的部分属性的含义有如下变化,
start_time:事件开始时间,在聚合事件中是指第一个系统事件的开始时间。end_time:事件结束时间,在聚合事件中是指(start_time + duration)。duration:事件执行时间,在聚合事件中是指所有系统事件实际执行时间的累加值。count:聚合事件中系统事件的数量,当值为 1 时,聚合事件就等价于一个系统事件。- 扩展的事件属性:在聚合事件中是指第一个系统事件的扩展属性。
L7Probe 介绍
定位:L7流量观测,覆盖常见的HTTP1.X、PG、MySQL、Redis、Kafka、HTTP2.0、MongoDB、RocketMQ协议,支持加密流观测。
场景:覆盖Node、Container、Pod(K8S)三类场景。
代码框架设计
L7Probe
| --- included // 公共头文件
| --- connect.h // L7 connect对象定义
| --- pod.h // pod/container对象定义
| --- conn_tracker.h // L7协议跟踪对象定义
| --- protocol // L7协议解析
| --- http // HTTP1.X L7 message结构定义及解析
| --- mysql // mysql L7 message结构定义及解析
| --- pgsql // pgsql L7 message结构定义及解析
| --- bpf // 内核bpf代码
| --- L7.h // BPF程序解析L7层协议类型
| --- kern_sock.bpf.c // 内核socket层观测
| --- libssl.bpf.c // openSSL层观测
| --- gossl.bpf.c // GO SSL层观测
| --- cgroup.bpf.c // pod 生命周期观测
| --- pod_mng.c // pod/container实例管理(感知pod/container生命周期)
| --- conn_mng.c // L7 Connect实例管理(处理BPF观测事件,比如Open/Close事件、Stats统计)
| --- conn_tracker.c // L7 流量跟踪(跟踪BPF观测数据,比如send/write、read/recv等系统事件产生的数据)
| --- bpf_mng.c // BPF程序生命周期管理(按需、实时open、load、attach、unload BPF程序,包括uprobe BPF程序)
| --- session_conn.c // 管理jsse Session(记录jsse Session和sock连接的对应关系,上报jsse连接信息)
| --- L7Probe.c // 探针主程序
探针输出
| metrics_name | table_name | metrics_type | unit | metrics description |
|---|---|---|---|---|
| tgid | NA | key | NA | Process ID of l7 session. |
| client_ip | NA | key | NA | Client IP address of l7 session. |
| server_ip | NA | key | NA | Server IP address of l7 session. 备注:K8S场景支持Cluster IP转换成Backend IP |
| server_port | NA | key | NA | Server Port of l7 session. 备注:K8S场景支持Cluster Port转换成Backend Port |
| l4_role | NA | key | NA | Role of l4 protocol(TCP Client/Server or UDP) |
| l7_role | NA | key | NA | Role of l7 protocol(Client or Server) |
| protocol | NA | key | NA | Name of l7 protocol(http/http2/mysql...) |
| ssl | NA | label | NA | Indicates whether an SSL-encrypted l7 session is used. |
| bytes_sent | l7_link | gauge | NA | Number of bytes sent by a l7 session. |
| bytes_recv | l7_link | gauge | NA | Number of bytes recv by a l7 session. |
| segs_sent | l7_link | gauge | NA | Number of segs sent by a l7 session. |
| segs_recv | l7_link | gauge | NA | Number of segs recv by a l7 session. |
| throughput_req | l7_rpc | gauge | qps | Request throughput of l7 session. |
| throughput_resp | l7_rpc | gauge | qps | Response throughput of l7 session. |
| req_count | l7_rpc | gauge | NA | Request num of l7 session. |
| resp_count | l7_rpc | gauge | NA | Response num of l7 session. |
| latency_avg | l7_rpc | gauge | ns | L7 session averaged latency. |
| latency | l7_rpc | histogram | ns | L7 session histogram latency. |
| latency_sum | l7_rpc | gauge | ns | L7 session sum latency. |
| err_ratio | l7_rpc | gauge | % | L7 session error rate. |
| err_count | l7_rpc | gauge | NA | L7 session error count. |
动态控制
控制观测Pod范围
- REST->gala-gopher。
- gala-gopher->L7Probe。
- L7Probe 基于Pod获取相关Container。
- L7Probe 基于Container获取其 CGroup id(cpuacct_cgrp_id),并写入object模块(API: cgrp_add)。
- Socket系统事件上下文中,获取进程所属CGroup(cpuacct_cgrp_id),参考Linux代码(task_cgroup)。
- 观测过程中,通过object模块过滤(API: is_cgrp_exist)。
控制观测能力
- REST->gala-gopher。
- gala-gopher->L7Probe。
- L7Probe根据输入参数动态的开启、关闭BPF观测能力(包括吞吐量、时延、Trace、协议类型)。
观测点
内核Socket系统调用
TCP相关系统调用
// int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
// int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
// int accept4(int sockfd, struct sockaddr *addr, socklen_t *addrlen, int flags);
// ssize_t write(int fd, const void *buf, size_t count);
// ssize_t send(int sockfd, const void *buf, size_t len, int flags);
// ssize_t read(int fd, void *buf, size_t count);
// ssize_t recv(int sockfd, void *buf, size_t len, int flags);
// ssize_t writev(int fd, const struct iovec *iov, int iovcnt);
// ssize_t readv(int fd, const struct iovec *iov, int iovcnt);
TCP&UDP相关系统调用
// ssize_t sendto(int sockfd, const void *buf, size_t len, int flags, const struct sockaddr *dest_addr, socklen_t addrlen);
// ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen);
// ssize_t sendmsg(int sockfd, const struct msghdr *msg, int flags);
// ssize_t recvmsg(int sockfd, struct msghdr *msg, int flags);
// int close(int fd);
注意点:
- read/write、readv/writev 与普通的文件I/O操作会混淆,通过观测内核security_socket_sendmsg函数区分FD是否属于socket操作。
- sendto/recvfrom、sendmsg/recvmsg TCP/UDP均会使用,参考下面手册的介绍。
- sendmmsg/recvmmsg、sendfile 暂不支持。
sendto manual :If sendto() is used on a connection-mode (SOCK_STREAM, SOCK_SEQPACKET) socket, the arguments dest_addr and addrlen are ignored (and the error EISCONN may be returned when they are not NULL and 0), and the error ENOTCONN is returned when the socket was not actually connected. otherwise, the address of the target is given by dest_addr with addrlen specifying its size.
sendto 判断dest_addr参数为NULL则为TCP,否则为UDP。
recvfrom manual:The recvfrom() and recvmsg() calls are used to receive messages from a socket, and may be used to receive data on a socket whether or not it is connection-oriented.
recvfrom判断src_addr参数为NULL则为TCP,否则为UDP。
sendmsg manual:The sendmsg() function shall send a message through a connection-mode or connectionless-mode socket. If the socket is a connectionless-mode socket, the message shall be sent to the address specified by msghdr if no pre-specified peer address has been set. If a peer address has been pre-specified, either themessage shall be sent to the address specified in msghdr (overriding the pre-specified peer address), or the function shall return -1 and set errno to [EISCONN]. If the socket is connection-mode, the destination address in msghdr shall be ignored.
sendmsg判断msghdr->msg_name参数为NULL则为TCP,否则为UDP。
recvmsg manual: The recvmsg() function shall receive a message from a connection-mode or connectionless-mode socket. It is normally used with connectionless-mode sockets because it permits the application to retrieve the source address of received data.
recvmsg判断msghdr->msg_name参数为NULL则为TCP,否则为UDP。
libSSL API
SSL_write
SSL_read
Go SSL API
JSSE API
sun/security/ssl/SSLSocketImpl$AppInputStream
sun/security/ssl/SSLSocketImpl$AppOutputStream
JSSE观测方案
加载JSSEProbe探针
main函数中通过l7_load_jsse_agent加载JSSEProbe探针。
轮询观测白名单(g_proc_obj_map_fd)中的进程,若为java进程,则通过jvm_attach将JSSEProbeAgent.jar加载到此观测进程上。加载成功后,该java进程会在指定观测点(参见JSSE API)将观测信息输出到jsse-metrics输出文件(/tmp/java-data-
处理JSSEProbe消息
l7_jsse_msg_handler线程中处理JSSEProbe消息。
轮询观测白名单(g_proc_obj_map_fd)中的进程,若该进程有对应的jsse-metrics输出文件,则按行读取此文件并解析、转换、上报jsse读写信息。
1. 解析jsse读写信息
jsse-metrics.txt的输出格式如下,从中解析出一次jsse请求的pid, sessionId, time, read/write操作, IP, port, payload信息:
|jsse_msg|662220|Session(1688648699909|TLS_AES_256_GCM_SHA384)|1688648699989|Write|127.0.0.1|58302|This is test message|
解析出的原始信息存储于session_data_args_s中。
2. 转换jsse读写信息
将session_data_args_s中的信息转换为sock_conn和conn_data。
转化时需要查询如下两个hash map:
session_head:记录jsse连接的session Id和sock connection Id的对应关系。若进程id和四元组信息一致,则认为session和sock connection对应。
file_conn_head:记录java进程的最后一个sessionId,以备L7probe读jsseProbe输出时,没有从请求开头开始读取,找不到sessionId信息。
3. 上报jsse读写信息
将sock_conn和conn_data上报到map中。
sliprobe 介绍
基于 ebpf 采集并周期性上报容器粒度的 SLI 指标。
特性
- 按照容器粒度采集周期内CPU调度事件的时延总计和统计直方图,关注的事件包括:调度等待,主动睡眠,锁/IO引起的阻塞,调度延迟,长系统调用等
- 按照容器粒度采集周期内Memory分配事件的时延总计和统计直方图,关注的事件包括:内存回收,换页,内存规整等
- 按照容器粒度采集周期内BIO层IO操作的时延总计和统计直方图
使用说明
启动命令示例:指定上报周期为15秒,观测容器id为abcd12345678和abcd87654321的两个容器的SLI指标。
curl -X PUT http://localhost:9999/sli -d json='{"params":{"report_period":15}, "snoopers":{"container_id":[{"container_id": "abcd12345678","abcd87654321"}]}, "state":"running"}'
代码逻辑
总体思路
用户态接收待观测的容器列表,将容器的cpuacct子系统目录inode记录在ebpf map中,共享给内核态。
通过ebpf kprobe/tracepoint跟踪相关内核事件,判断当前进程是否属于待观测范围,记录事件类型,时间戳等信息。每隔一定周期将同一cgroup内进程的SLI指标进行聚合上报。
用户态接收并打印内核态上报的SLI指标信息。
SLI指标计算方式
CPU SLI
cpu_wait
在sched_stat_wait观测点,获取第二个参数delay的值
cpu_sleep
在sched_stat_sleep观测点,获取第二个参数delay的值
cpu_iowait
在sched_stat_blocked观测点,判断当前进程in_iowait,则获取第二个参数delay的值
cpu_block
在sched_stat_blocked观测点,判断当前进程非in_iowait,则获取第二个参数delay的值
cpu_rundelay
在sched_switch观测点,通过第三个参数next获取将被调度进程的run_delay值:next->sched_info.run_delay,记录在task_sched_map中。计算同一进程两次被调度时run_delay的差值
cpu_longsys
在sched_switch观测点,通过第三个参数next获取将被调度进程的task结构体,从task结构体中获取上下文切换次数(nvcsw+nivcsw)和用户态执行时间utime。如果同一进程两次被调度时的上下文切换次数和用户态执行时间都不变,则说明在该进程在执行一个较长的系统调用,累积该进程处在内核态的时间
MEM SLI
mem_reclaim
计算mem_cgroup_handle_over_high函数返回时间戳和进入时间戳的差值
计算mm_vmscan_memcg_reclaim_end观测点和mm_vmscan_memcg_reclaim_begin观测点时间戳的差值
mem_swapin
计算do_swap_page函数返回时间戳和进入时间戳的差值
mem_compact
计算try_to_compact_pages函数返回时间戳和进入时间戳的差值
IO SLI
bio_latency
计算进入bio_endio函数和触发block_bio_queue观测点的时间戳差值
计算进入bio_endio函数和退出generic_make_request_checks函数的时间戳差值
使用方法
外部依赖软件部署
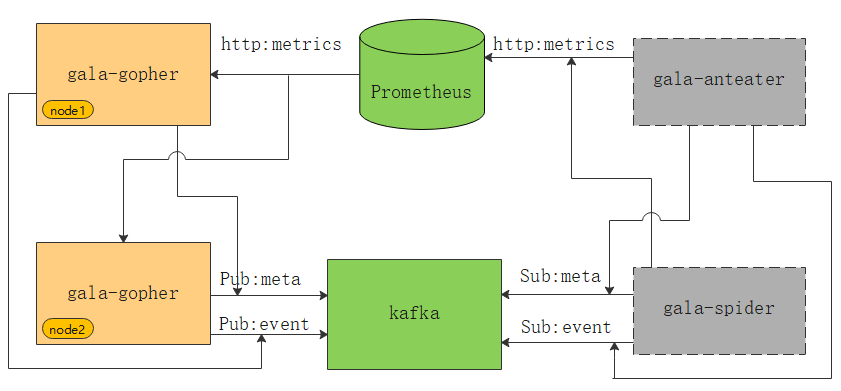
如上图所示,绿色部分为gala-gopher的外部依赖组件。gala-gopher会将指标数据metrics输出到prometheus,将元数据metadata、异常事件event输出到kafka,灰色部分的gala-anteater和gala-spider会从prometheus和kafka获取数据。
说明:安装kafka、prometheus软件包时,需要从官网获取安装包进行部署。
输出数据
指标数据metrics
Prometheus Server内置了Express Browser UI,用户可以通过PromQL查询语句查询指标数据内容。详细教程参见官方文档:Using the expression browser。示例如下:
指定指标名称为
gala_gopher_tcp_link_rcv_rtt,UI显示的指标数据为:gala_gopher_tcp_link_rcv_rtt{client_ip="x.x.x.165",client_port="1234",hostname="openEuler",instance="x.x.x.172:8888",job="prometheus",machine_id="1fd3774xx",protocol="2",role="0",server_ip="x.x.x.172",server_port="3742",tgid="1516"} 1元数据metadata
可以直接从kafka消费topic为
gala_gopher_metadata的数据来看。示例如下:# 输入请求 ./bin/kafka-console-consumer.sh --bootstrap-server x.x.x.165:9092 --topic gala_gopher_metadata # 输出数据 {"timestamp": 1655888408000, "meta_name": "thread", "entity_name": "thread", "version": "1.0.0", "keys": ["machine_id", "pid"], "labels": ["hostname", "tgid", "comm", "major", "minor"], "metrics": ["fork_count", "task_io_wait_time_us", "task_io_count", "task_io_time_us", "task_hang_count"]}异常事件event
可以直接从kafka消费topic为
gala_gopher_event的数据来看。示例如下:# 输入请求 ./bin/kafka-console-consumer.sh --bootstrap-server x.x.x.165:9092 --topic gala_gopher_event # 输出数据 {"timestamp": 1655888408000, "meta_name": "thread", "entity_name": "thread", "version": "1.0.0", "keys": ["machine_id", "pid"], "labels": ["hostname", "tgid", "comm", "major", "minor"], "metrics": ["fork_count", "task_io_wait_time_us", "task_io_count", "task_io_time_us", "task_hang_count"]}





