Go优化介绍
介绍
GO编译器是Go语言(又称Golang)的核心工具之一,负责将可读的Go源代码转换为计算机可以执行的机器码。它以高效、简洁和集成度高而著称。
新增特性列表
| 序号 | 特性名称 | 描述 | 使用说明 |
|---|---|---|---|
| 1 | hashmap哈希匹配假阳性消除优化 | 消除hashmap短哈希快速匹配时的假阳性现象 | GOARM64=v8.5,intrinsicmatchh2 |
| 2 | hashtriemap树结构优化 | 扩大hashtriemap的子节点数量,降低树高 | GOEXPERIMENT=widetrie |
| 3 | crc32c优化 | 优化ARM64上crc32c汇编实现(多路并行CRC32CX指令+循环展开),运行期由cpu.ARM64.HasCRC32自动启用 | 默认启用 |
| 4 | step函数优化 | 优化step函数的实现 | GOEXPERIMENT=stepopt |
| 5 | 禁用复制哈希值 | 回退上游一处导致性能劣化的map实现改动 | GOEXPERIMENT=revertcopyhashkeys |
| 6 | SSA比较指令模式优化 | 增加SSA重写与比较指令模式优化规则 | -gcflags="all=-aggressivepatterns" |
| 7 | pprof支持PMU/BRBE采样 | 在pprof中新增PMU硬件事件采样与BRBE分支追踪能力 | API/HTTP,详见使用说明 |
| 8 | forceinline优化 | 使能mallocgc等子函数的强制内联 | -gcflags="all=-d forceinline=1" |
| 9 | pagesize优化 | 增大Go堆内存分配的页大小至16K | GOEXPERIMENT=pageshift14 |
| 10 | span初始化清零 | 首次使用span时一次性清空整个span内存 | GOEXPERIMENT=clearspan |
| 11 | tinysize调整 | 将tiny分配单元由16字节增大为32字节 | GOEXPERIMENT=tinysize |
| 12 | GC后台CPU利用率可配置 | 将GC后台目标CPU利用率做成可配置(GOGCRATIO/100,默认25) | GOGCRATIO=25 |
| 13 | reflect读锁快速路径 | reflect.FuncOf缓存命中时走读锁快速路径 | GOEXPERIMENT=reflectrwlock |
| 14 | 条件比较指令优化 | 将嵌套条件分支转换为CCMP/CCMN指令 | -gcflags="all=-ccmp_gen" |
| 15 | LoopRotate优化增强 | 增强循环旋转,含嵌套循环原位保留 | -gcflags="all=-aggressivelooprotate" |
| 16 | atomic优化 | 使用原子操作替换dmb指令更新freeIndexForScan | GOEXPERIMENT=atomicvar |
| 17 | 内存prefetch优化 | 在mallocgc快速路径中插入prefetch操作 | GOEXPERIMENT=prefetchmalloc |
| 18 | SVE指令支持 | 汇编器新增SVE寄存器解析与指令编码,运行期由cpu.ARM64.HasSVE决定 | 默认启用(汇编器) |
| 19 | []byte(string([]byte))优化 | 将 []byte(string([]byte)) 转换为 makeslicecopy,减少内存分配 | -gcflags="all=-bytesstringbytesopt" |
| 20 | span page数量优化 | 鲲鹏平台增大span占用的page数量 | GOARM64=v8.2,kpmemopt |
| 21 | malloc优化参数打印 | 打印malloc优化参数(pageSize等),用于诊断 | GOEXPERIMENT=mallocoptprint |
| 22 | DSE优化增强 | 增强死存储消除(DSE)的覆盖场景 | -gcflags="all=-aggressivedse" |
| 23 | memmove函数优化 | 通过地址对齐、128位向量指令与循环展开优化内存拷贝 | GOEXPERIMENT=memmoveopt |
| 24 | PGO多级内联 | PGO内联按内联链中实际边的热度决策,挖掘嵌套调用的内联收益 | -gcflags="all=-d pgoinline=2"(需-pgo) |
| 25 | memmove范围预取优化 | 在memmove优化基础上使能RPRFM范围预取指令 | GOEXPERIMENT=memmoveopt GOARM64=v8.9,rprfm |
| 26 | ARM64 LDP/STP指令优化 | 连续访存使用LDP/STP合并LDR/STR | -gcflags="all=-d aarch64ldst=all" |
| 27 | 基本块分支预测重排 | 按分支预测信息重排基本块 | -gcflags="all=-d blockpredict=2" |
| 28 | RCpc特性使能 | 针对load-acquire场景使能LDAPR系列指令 | GOARM64=v8.3,rcpc |
| 29 | Prove优化增强 | 增强边界检查证明,消除更多边界检查 | -gcflags="all=-aggressiveprove" |
| 30 | bytealg汇编函数切换 | 将bytealg汇编由ABI0切换为ABIInternal约定 | GOARM64=v8.2,abiinternal |
| 31 | 函数对齐 | 设置函数对齐字节数,优化指令缓存对齐 | -ldflags="all=-funcalign=32" |
特性使用说明
hashmap哈希匹配假阳性消除优化
在hashmap中,lookup分为短哈希匹配和key匹配两步,当且仅当短哈希匹配时才会进行key匹配。当前开源代码中,短哈希匹配有1/128的概率出现假阳性(应当返回false,实际返回true),该现象不会导致正确性错误,但会导致完整key比较次数增加。此优化通过指令层面的重写,优化了短哈希匹配算法,彻底消除了假阳性现象,可提升hashmap的性能。
# 进行业务编译或单例测试
GOARM64="v8.5,intrinsicmatchh2" GOMAXPROCS=1 go test -bench=.hashtriemap树结构优化
在sync.hashtriemap中,增加每个节点的子节点数(由16叉树变更为128叉树),可有效降低树高,减少增删查改数据时的循环次数。
# 进行业务编译或单例测试
GOEXPERIMENT="widetrie" GOMAXPROCS=1 go test -bench=HashTrieMap -v -run=^$ ./internal/synccrc32c优化
针对ARM64平台优化crc32c(Castagnoli多项式)的汇编实现,采用多路并行的CRC32CX指令配合循环展开,提升大数据块的CRC32C校验吞吐。该优化默认启用,无需任何编译选项或环境变量,运行期由cpu.ARM64.HasCRC32自动判断是否使用,在不支持CRC32指令的平台上自动回退。
# 无需特殊选项,crc32c 优化默认启用;可直接跑校验性能
GOMAXPROCS=1 go test -bench=BenchmarkCRC32 -v -run=^$ hash/crc32step函数优化
step中的readvarint函数,循环次数集中在1次到2次(占比超99.9%),针对此现象对循环进行展开,讨论1次循环和2次循环的场景,并使用ldp指令优化读取。
# 进行业务编译或单例测试
GOEXPERIMENT="stepopt" GOMAXPROCS=1 go test -bench=BenchmarkMalloc -v -run=^$ runtime/禁用复制哈希值
回退社区主干中一处“复制key的哈希值而非key本身”的改动,该改动在部分场景下引入性能劣化,回退后恢复原有map实现的性能。
# 进行业务编译或单例测试
GOEXPERIMENT="revertcopyhashkeys" GOMAXPROCS=1 go test -bench=BenchmarkMapAccess -v -run=^$ runtime/SSA比较指令模式优化
在SSA层增加重写与模式匹配规则,如操作数与0的比较、切片边界(SUB/SUBconst、NEG(SUB))等模式优化。
# 进行业务编译
go build -gcflags="all=-aggressivepatterns" .pprof支持PMU/BRBE采样
在pprof中新增对PMU(性能监控单元)硬件事件采样与BRBE(分支记录缓冲区,Branch Record Buffer Extension)分支追踪的支持,可基于CPU硬件事件(如cycles、cache-miss等)进行性能剖析,并采集分支跳转记录用于热点分析。提供API与HTTP两种接入方式。
// API 方式:在程序中按 PMU 事件采样(指定硬件事件、采样频率、是否开启 BRBE)
import "runtime/pprof"
// pprof.StartPMUProfile(w, *PMUAttr)
// ... 采样结束后 pprof.StopPMUProfile()# HTTP 方式(程序内 import _ "net/http/pprof"):按 PMU 事件 + BRBE 分支追踪采集
go tool pprof "http://localhost:6060/debug/pprof/profile?event=<事件>&freq=<频率>&brbe=true&seconds=30"forceinline优化
使能mallocgc等子函数的强制内联,消除热点路径上的函数调用开销。
# 进行业务编译
go build -gcflags="all=-d forceinline=1" .pagesize优化
将Go堆内存分配的页大小扩大至16K,改善内存分配的局部性。注意该特性与kpmemopt(span page数量优化)均调整页/span规格,二者不建议同时开启:在支持GOARM64=v9.0的设备(如鲲鹏950)上优先使用kpmemopt,否则使用pageshift14。
# 进行业务编译或单例测试
GOEXPERIMENT="pageshift14" GOMAXPROCS=1 go test -bench=BenchmarkMalloc -v -run=^$ runtime/span初始化清零
在span首次分配使用时,一次性清空整个span内存,避免逐对象清零带来的重复开销。
# 进行业务编译或单例测试
GOEXPERIMENT="clearspan" GOMAXPROCS=1 go test -bench=BenchmarkMalloc -v -run=^$ runtime/tinysize调整
将tiny分配器的分配单元由16字节增大为32字节,减少小对象分配时的span申请次数。
# 进行业务编译或单例测试
GOEXPERIMENT="tinysize" GOMAXPROCS=1 go test -bench=BenchmarkMalloc -v -run=^$ runtime/GC后台CPU利用率可配置
将GC后台标记的目标CPU利用率(gcBackgroundUtilization,社区固定为25%)做成可通过环境变量配置,取值为GOGCRATIO/100。GOGCRATIO取值范围1–99,默认25。增大该值可让后台GC占用更多CPU、更快完成标记;减小则相反。注意该项为运行期环境变量,而非构建期选项。
# 运行期设置(注意是运行期环境变量,非构建期)
GOGCRATIO=25 ./your_programreflect读锁快速路径
在reflect.FuncOf的函数类型缓存命中时,走读锁(RLock)快速路径而非互斥锁,降低高并发反射调用下的锁竞争。
# 进行业务编译或单例测试
GOEXPERIMENT="reflectrwlock" GOMAXPROCS=1 go test -bench=. -v -run=^$ reflect条件比较指令优化
在ARM64平台上,将嵌套的条件分支转换为条件比较指令CCMP/CCMN,执行if-conversion优化,减少分支预测错误。建议配合函数对齐(-funcalign)一起使用。
# 进行业务编译
go build -gcflags="all=-ccmp_gen" -ldflags="all=-funcalign=32" .LoopRotate优化增强
增强循环旋转优化,将内层循环的基本块保留在外层循环中间,减少基本块间的跳转(含嵌套循环的原位保留)。
# 进行业务编译
go build -gcflags="all=-aggressivelooprotate" .atomic优化
使用原子操作替换DMB屏障来更新freeIndexForScan,在保证GC扫描内存可见性的前提下降低同步开销。该特性为ARM64平台专用。
# 进行业务编译或单例测试
GOEXPERIMENT="atomicvar" GOMAXPROCS=1 go test -bench=BenchmarkMalloc -v -run=^$ runtime/内存prefetch优化
在mallocgc的快速路径中插入prefetch操作,提前预取后续将要访问的内存地址,降低cache miss。
# 进行业务编译或单例测试
GOEXPERIMENT="prefetchmalloc" GOMAXPROCS=1 go test -bench=BenchmarkMalloc -v -run=^$ runtime/SVE指令支持
汇编器新增对SVE(Scalable Vector Extension,可扩展向量扩展)寄存器解析与指令编码的支持,使得可在Plan9汇编中直接书写SVE向量指令(如whilele、ld1h、uaddv、ptrue等)。该能力默认编入工具链,无需开关;是否在运行期执行相关代码路径由cpu.ARM64.HasSVE决定,不支持SVE的平台自动跳过。
该特性为工具链/汇编器能力,无需编译选项;在含 SVE 指令的 .s 汇编文件中即可使用,
运行期由 cpu.ARM64.HasSVE 自动判断是否走 SVE 路径。[]byte(string([]byte))优化
识别[]byte(string([]byte))模式并直接转换为makeslicecopy调用,避免不必要的临时转换与内存分配。
# 进行业务编译
go build -gcflags="all=-bytesstringbytesopt" .span page数量优化
内存页分区扩展优化方案的核心在于67种不同sizeclasses的生成与优化。这些sizeclasses在编译业务代码之前生成,随后与runtime库和内存管理器的内容结合进行编译,最终与业务代码链接形成执行文件。当需要分配内存时,内存管理器会依据sizeclasses信息变量,确定对象所需的页表数据量,从而有效减少在大量小对象分配上的耗时。
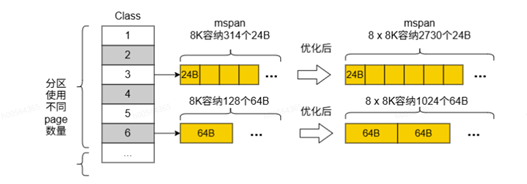
该设计的改进,扩大了单个mspn可以容纳的对象个数,如上图所示,对于24B的对象类型,从8192B中可划分出314个24B空闲对象,而从8 * 8192B中可划分出高达2730个空闲的对象空间,比原生空间扩展多倍。在大量的使用小对象的场景下,能够有效的减少申请和操作mspn的次数。
选项使能:通过为 GOARM64 增加 kpmemopt 后缀开启该优化,构建工具链时会自动联动 GOEXPERIMENT=pagenum;GOARM64 版本需不低于 v8.2,且仅在鲲鹏(Kunpeng 920/920E/950)+ SVE 平台上生效,其余平台自动回退到默认布局、零影响。
# 编译带 kpmemopt 的工具链(自动联动 GOEXPERIMENT=pagenum)
GOARM64="v8.2,kpmemopt" ./make.bash
# 进行业务编译或单例测试
GOARM64="v8.2,kpmemopt" GOMAXPROCS=1 go test -bench=BenchmarkMalloc -v -run=^$ runtime/malloc优化参数打印
打印malloc相关优化的运行参数(如pageSize、span的page数量等),用于诊断与确认内存优化是否按预期生效。该特性为诊断用途,非性能优化,生产构建可不开启。
# 诊断:打印 malloc 优化参数
GOEXPERIMENT="mallocoptprint" GOMAXPROCS=1 go test -bench=BenchmarkMalloc -v -run=^$ runtime/DSE优化增强
增强死存储消除(Dead Store Elimination)的覆盖场景,例如指针加常量偏移、store后立即load(store-to-load转发)等,消除更多冗余存储。
# 进行业务编译
go build -gcflags="all=-aggressivedse" .memmove函数优化
针对ARM64平台重写memmove实现,通过拷贝地址对齐、使用128位向量指令(FLDPQ/FSTPQ)以及循环展开,提升大块内存拷贝的吞吐。
# 进行业务编译或单例测试
GOEXPERIMENT="memmoveopt" GOMAXPROCS=1 go test -bench=BenchmarkMemmove -v -run=^$ runtime/PGO多级内联
扩展PGO(Profile-Guided Optimization,基于性能剖析的优化)的内联策略,使其支持多级调用链:按内联链中实际边(如F2→F3)的热度而非仅顶层调用决策是否内联,从而挖掘嵌套调用的内联收益。需先开启PGO(如 -pgo=auto)再配合使用。
# 需开启 PGO(如 -pgo=auto),再启用多级内联
go build -pgo=auto -gcflags="all=-d pgoinline=2" .memmove范围预取优化
在memmove优化(memmoveopt)的基础上,对满足条件的大块拷贝使能RPRFM范围预取指令,进一步降低访存延迟。该特性需与memmoveopt配合使用,且要求GOARM64版本不低于v8.9(低于v8.9时自动关闭)。
# 进行业务编译或单例测试
GOEXPERIMENT="memmoveopt" GOARM64="v8.9,rprfm" GOMAXPROCS=1 go test -bench=BenchmarkMemmove -v -run=^$ runtime/ARM64 LDP/STP指令优化
对连续的内存地址加载或存储,使用LDP/STP指令替换成对的LDR/STR指令,减少访存指令数。可选值:none、off、load、store、all、on。
# 进行业务编译
go build -gcflags="all=-d aarch64ldst=all" .基本块分支预测重排
针对分支属性likely / unlikely / errorlikely,按分支预测信息对基本块进行排布优化,减少跳转。
# 进行业务编译
go build -gcflags="all=-d blockpredict=2" .RCpc特性使能
针对load-acquire场景,使能LDAPR系列RCpc指令优化LoadAcq操作,相较DMB屏障可降低内存访问延迟。
# 进行业务编译或单例测试
GOARM64="v8.3,rcpc" GOMAXPROCS=1 go test -bench=. -v -run=^$ sync/atomicProve优化增强
增加额外的边界检查证明规则,进一步证明数据上界并消除更多边界检查(如mallocgc中的死边界检查)。
# 进行业务编译
go build -gcflags="all=-aggressiveprove" .bytealg汇编函数切换
将bytealg中的Count、IndexByte、Index等汇编函数由ABI0(堆栈调用约定)切换为ABIInternal(寄存器调用约定),减少函数调用开销。
# 进行业务编译或单例测试
GOARM64="v8.2,abiinternal" GOMAXPROCS=1 go test -bench=. -v -run=^$ bytes函数对齐
设置函数对齐字节数(须为2的幂),优化指令缓存(icache)对齐,提升函数执行性能。常与条件比较指令优化(ccmp_gen)配合使用。
# 进行业务编译
go build -ldflags="all=-funcalign=32" .遵循 木兰宽松许可证第2版(MulanPSL2)
