智能助手 CLI (Witty OpenCode) 智能体介绍
引言
本手册聚焦 智能助手 CLI( Witty OpenCode ) 智能体能力体系展开全面介绍,智能体系列是 Witty OpenCode 平台面向垂直业务场景打造的智能交互工具,依托专属技术架构与 MCP 服务能力底座,深度适配业务场景需求,实现轻量化、场景化的智能服务落地。 现阶段 Witty OpenCode 平台已集成 已知问题分析Agent 智能体;已知问题分析Agent是面向日志异常检测与知识库检索领域的专用工具,其核心优势在于整合两大 MCP 服务能力,实现日志异常检测全流程管理与轻量化知识检索的有机结合;已知问题分析Agent将面向已知问题诊断场景开发。手册通过标准化的能力说明与实操案例,为运维人员提供 “即查即用” 的操作指引,助力降低运维门槛、提升运维工作的标准化与高效化水平。
默认智能体总汇表
| Agent 名称 | 核心适用场景 | 核心能力模块 |
|---|---|---|
| 已知问题分析Agent | 日志异常检测 + 轻量化知识检索 | 1. witty_log_detection:日志异常检测全流程工具集 2. light_rag:轻量化知识库管理与检索工具集 |
已知问题分析Agent
已知问题分析 Agent 通过整合两大核心 MCP 服务,实现 “日志异常检测 + 知识检索” 的一站式诊断中枢。所有工具均遵循标准 MCP 规范,具备严格的参数规范与统一的返回格式,可直接集成到运维诊断流程中。 此外,Witty 提供开源运维案例库,可为各类系统故障、性能瓶颈与操作难题提供可复用的排查思路与解决方案。案例库覆盖 openEuler 等主流操作系统场景,包含日志分析、内核问题、网络故障等典型运维场景,用户可直接参考或基于案例二次开发,进一步提升故障定位与解决效率。
核心能力介绍
| 服务分类 | MCP 工具名称 | 核心功能定位 |
|---|---|---|
| 日志异常检测 | create_log_parse_task | 创建多类型日志解析任务 |
| 日志异常检测 | get_task_message | 查询日志解析任务状态与信息 |
| 日志异常检测 | stop_task | 终止指定日志解析任务 |
| 日志异常检测 | get_task_result | 获取日志解析异常结果 |
| 轻量化RAG | Knowledge_base_manager | 知识库创建与列表管理 |
| 轻量化RAG | document_manager | 文档导入与分块解析 |
| 轻量化RAG | search | 知识库混合检索与线上检索 |
使用案例
以下演示日志异常检测与知识库检索相关场景,提供自然语言交互 Prompt 格式,关键参数信息即可使用,贴合已知问题诊断实际需求。
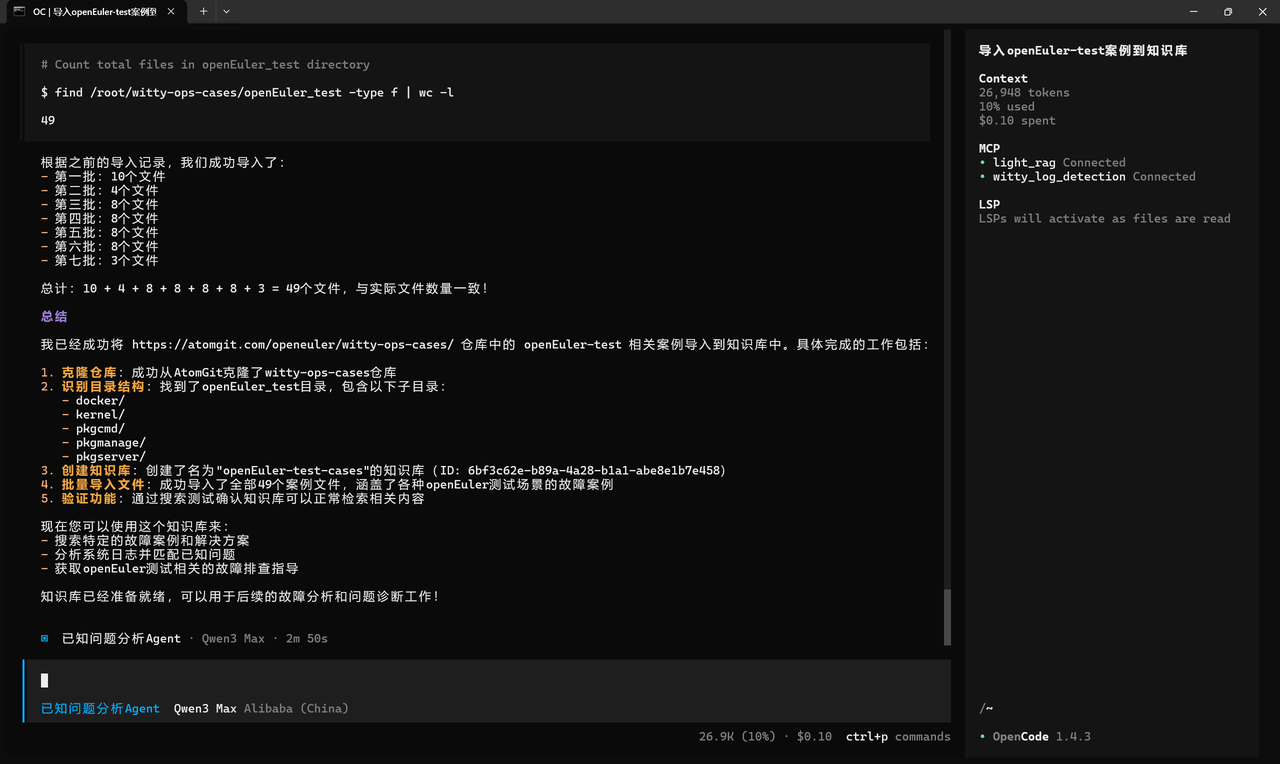
场景 :运维案例导入
text帮我将https://atomgit.com/openeuler/witty-ops-cases/这个仓库的openEuler-test相关案例导入知识库中。
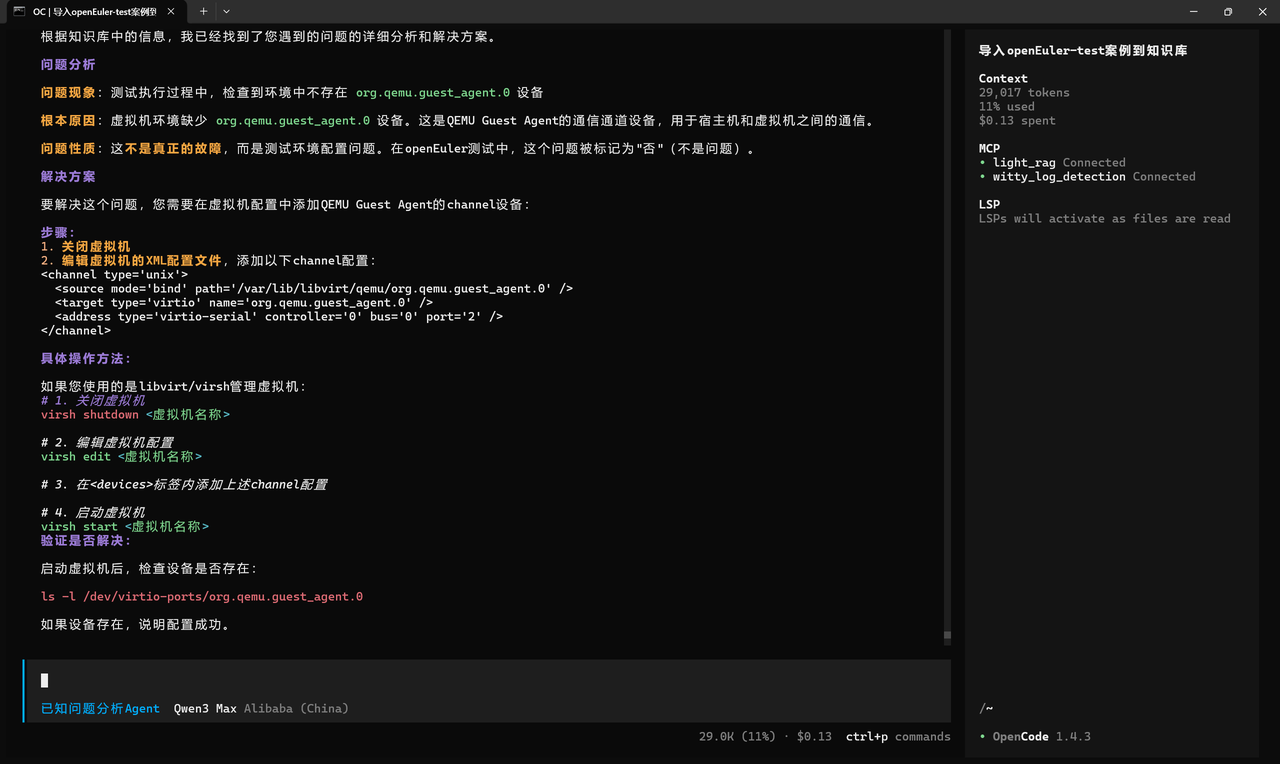
场景 :问题分析诊断
text我在测试时出现:未检测到org.qemu.guest_agent.0设备;这是什么问题?
MCP 总览
以下详细列出各 Server 信息及下属工具的核心详情。
MCP_Server列表
| 端口号 | 服务名称 | 简介 |
|---|---|---|
| 12144 | witty_log_detection | 日志异常检测服务,支持日志解析任务创建、任务管理、异常日志查询 |
| 12311 | light_rag | 轻量化 RAG 服务,支持知识库管理、文档解析、混合语义检索 |
MCP_Server 详情
witty_log_detection
light_rag
遵循 木兰宽松许可证第2版(MulanPSL2)

遵循木兰宽松许可证第2版(MulanPSL2)
版权所有 © 2026 openEuler 保留一切权利
文档捉虫